I am trying to clean html data using beautiful soup. I want to remove a set of tags along with the data associated in that tags which are consescutive starting from et_pb_row_inner et_pb_row_inner_2 to et_pb_row_inner et_pb_row_inner_22 .
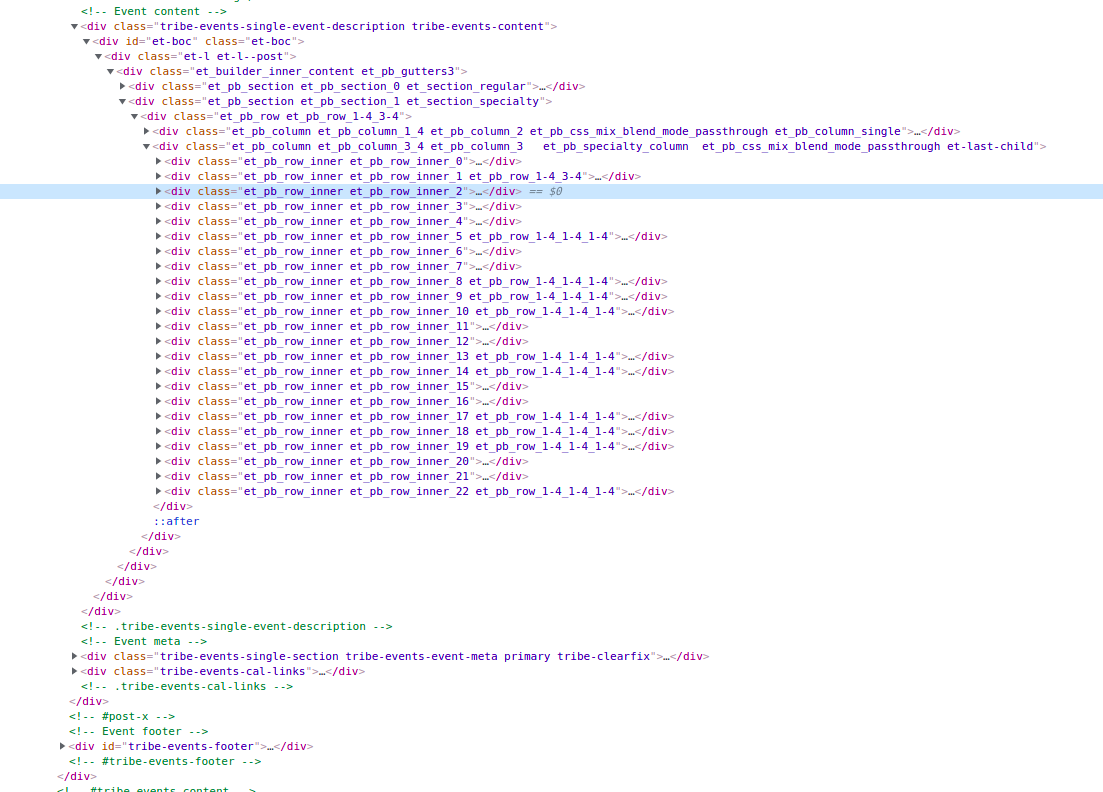
The code which i was trying is like this
Code
def madisonsymphony(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
for h in soup.find_all('header'):
try:
h.extract()
except:
pass
for f in soup.find_all('footer'):
try:
f.extract()
except:
pass
tophead = soup.find("div",{"id":"top-header"})
tophead.extract()
for x in range(2,23):
mydiv = soup.find("div", {"class": "et_pb_row_inner et_pb_row_inner_{}".format(x)})
mydiv.extract()
text = soup.getText(separator=u' ')
return text
I got it by individually specifying the class name using find(), but how is it possible to do in a general manner.
CodePudding user response:
You could use a regex to find all the <div> tags that have those attributes and end in 2 or higher.
So basically the regex r'et_pb_row_inner et_pb_row_inner_([2-9]|[\d]{2,}).*' is saying find all the et_pb_row_inner et_pb_row_inner_ that end in a single digit of 2 through 9 or is a digit in length of two or more.
def madisonsymphony(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
for h in soup.find_all('header'):
try:
h.extract()
except:
pass
for f in soup.find_all('footer'):
try:
f.extract()
except:
pass
tophead = soup.find("div",{"id":"top-header"})
tophead.extract()
for mydiv in soup.find_all("div", {"class":re.compile(r'et_pb_row_inner et_pb_row_inner_([2-9]|[\d]{2,}).*')}):
mydiv.extract()
text = soup.getText(separator=u' ')
return text
This way you don't need to hard code the range 2 through 21. It'll just go from 2 to whatever that last value is. The other way to do it is just use slicing.
def madisonsymphony(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
for h in soup.find_all('header'):
try:
h.extract()
except:
pass
for f in soup.find_all('footer'):
try:
f.extract()
except:
pass
tophead = soup.find("div",{"id":"top-header"})
tophead.extract()
mydivs = soup.find_all("div", {"class":re.compile(r'et_pb_row_inner et_pb_row_inner_.*')})
for mydiv in mydivs[2:]: # Start at the 2nd element in the list and continue to the end
mydiv.extract()
text = soup.getText(separator=u' ')
return text
Problem with that is you have to make the assumption theres a 0 and 1. If for whatever reason the attributes starts at 1, then youre keeping the 2, which would be the second element.