i have a datafame in input and i want to extract in column "localisation" the word in this list ["SECTION 11","CÔNE","BELLY"] and i have to create new column "word"
in the dataframe. If the word of the list exist in the the column "localisation" i fill the word in the column created "word".otherwise i put the full text in the column "word"
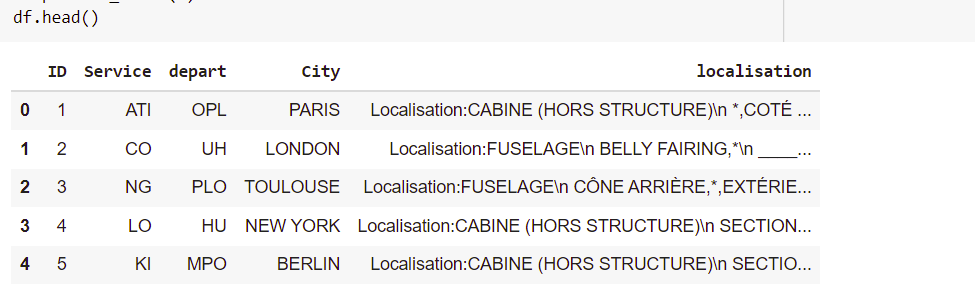
This my dataframe
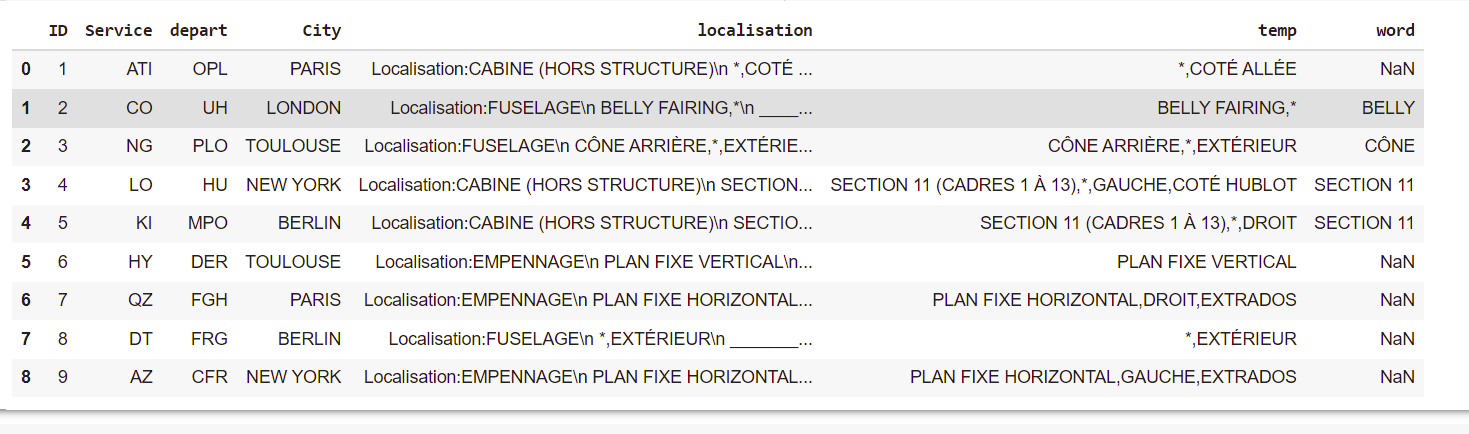
I create new column "word" I selected the line containing the words from the list I fill in the "word" column with the keywords found from the list
["SECTION 11","CÔNE","BELLY"]
df["temp"]=df["localisation"].str.extract("Localisation[\s]*:.*\n([^_\n]{3,})\n[^\n]*\n")
df["word"]=df["temp"].str.extract("(SECTION 11|CÔNE|BELLY)")
df["temp"]=df["localisation"].str.extract("Localisation[\s]*:.*\n([^_\n]{3,})\n[^\n]*\n")
df["word"]=df["temp"].str.extract("(SECTION 11|CÔNE|BELLY)")
my problem I can not put the full text if the word of the list is not found in the column "localization". I have null values in the lines or I have to put the full text
CodePudding user response:
You need to use .fillna with the df["localisation"] as argument:
df["word"]=df["localisation"].str.extract(r"\b(SECTION 11|CÔNE|BELLY)\b", expand=False).fillna(df["localisation"])
Note also that I suggested r"\b(SECTION 11|CÔNE|BELLY)\b", a regex with word boundaries to only match your alternatives as whole words. Note that word boundaries \b are Unicode-aware in Python re that is used behind the scenes in Pandas.
If you do not need the whole word search, you may keep using r"SECTION 11|CÔNE|BELLY".