I'm looking for a way to generate different data frames where a variable is distributed randomly among a set number of observations, but where the sum of those values adds up to a predetermined total. More specifically I'm looking for a way to distribute 20.000.000 votes among 15 political parties randomly. I've looked around the forums a bit but can't seem to find an answer, and while trying to generate the data on my own I've gotten nowhere; I don't even know where to begin. The distribution itself does not matter, though I'd love to be able to influence the way it distributes the votes.
Thank you :)
CodePudding user response:
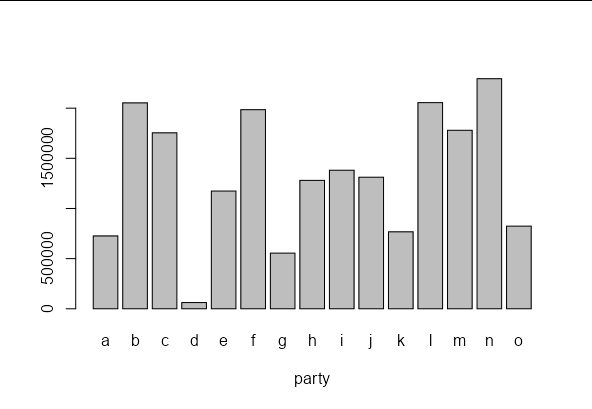
You could make a vector of 20,000,000 samples of the numbers 1 through 15 then make a table from them, but this seems rather computationally expensive, and will result in an unrealistically even split of votes. Instead, you could normalise the cumulative sum of 15 numbers drawn from a uniform distribution and multiply by 20 million. This will give a more realistic spread of votes, with some parties having significantly more votes than others.
my_sample <- cumsum(runif(15))
my_sample <- c(0, my_sample/max(my_sample))
votes <- round(diff(my_sample) * 20000000)
votes
#> [1] 725623 2052337 1753844 61946 1173750 1984897
#> [7] 554969 1280220 1381259 1311762 766969 2055094
#> [13] 1779572 2293662 824096
These will add up to 20,000,000:
sum(votes)
#> [1] 2e 07
And we can see quite a "natural looking" spread of votes.
barplot(setNames(votes, letters[1:15]), xlab = "party")
I'm guessing if you substitute rexp for runif in the above solution this would more closely match actual voting numbers in real life, with a small number of high-vote parties and a large number of low-vote parties.