I am using the auto data from R I need to plot the confidence intervals but it is a struggle, this is what I got so far:
I have created the model for linear regression
my_acc<-auto_df$acceleration
my_horse<-auto_df$horsepower
mydata <- data.frame(my_acc, my_horse )
car_linear_regression <- lm(my_acc ~ my_horse, mydata )
I have created the confidence intervals for ONE prediction as the exercise is asking
conf_int<-predict(car_linear_regression,newdata = data.frame(my_horse = 93.5),interval = 'confidence' )
#data.frame(my_horse = 93.5) must be the same as in the original dataframe
pred_int<-predict(car_linear_regression,newdata = data.frame(my_horse = 93.5),interval = 'prediction' )
Then I am trying to plot everthing together but I am totally stuck, I can plot the data with the regression line, but I only get this error
Error in xy.coords(x, y) : 'x' and 'y' lengths differ
plot(my_acc ~ my_horse , data = mydata, pch = 20, cex = 1.5, col="blue", xlab=" car horsepower", ylab = "acceleration secs to 100km/h", main = "Confidence intervals and prediction intervals")
abline(car_linear_regression, lwd = 5, col="red" )
lines(mydata$my_horse, conf_int[,"lwr"], col="red", type="b", pch=" ")
CodePudding user response:
For the plot you need definitely predictions on the whole range, i.e. min max of horespower.
data('Auto', package='ISLR')
fo <- acceleration ~ horsepower ## formula object for re-use
fit <- lm(fo, Auto)
We will need a sequence over the range of predictor horsepower, so a glance into summary is helpful.
summary(Auto)
Then we create a sequence for plotting with a reasonable step size. This will be what lines uses to plot the lines.
n_data <- with(Auto, seq(min(horsepower), max(horsepower), by=1))
Now calculate predictions using the sequences,
conf_int <- predict(fit, newdata=list(horsepower=n_data),
interval='confidence', level=.99)
pred_int <- predict(fit, newdata=list(horsepower=n_data),
interval='prediction', level=.99)
and plot the guy.
plot(fo, data=Auto, pch=20, cex=1, col="blue",
xlab=" car horsepower", ylab="acceleration secs to 100km/h",
main="Confidence intervals and prediction intervals", xlim=hp_rg)
abline(fit, lwd=2, col="red")
matlines(n_data, conf_int[, 2:3], lty='dashed', col="red", lwd=2)
matlines(n_data, pred_int[, 2:3], lty='dashed', col="green", lwd=2)
legend('topright', legend=c('conf_int', 'pred_int'), col=c("red", "green"),
lty=2, lwd=2)
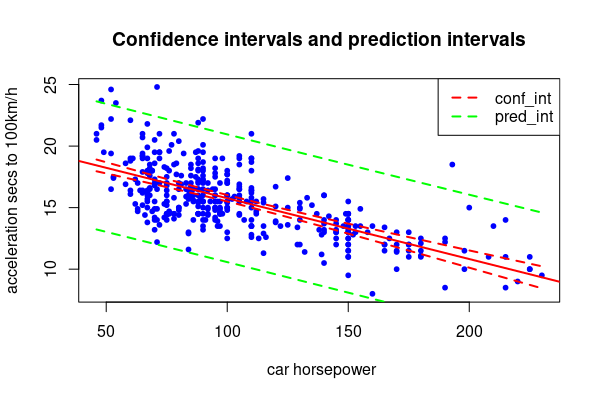
Note that I've used matlines here which is more concise, you could also use lines(n_data, conf_int[, 2], ..), lines(n_data, conf_int[, 3], ..) if you want.
CodePudding user response:
You can use ggplot2 and attach different data to different plotting layers or just base R:
library(tidyverse)
auto_df <- read_delim(
file = "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data",
delim = " ",
col_names = FALSE
)
#>
#> ── Column specification ────────────────────────────────────────────────────────
#> cols(
#> X1 = col_double(),
#> X2 = col_character(),
#> X3 = col_character(),
#> X4 = col_character(),
#> X5 = col_character(),
#> X6 = col_character(),
#> X7 = col_character(),
#> X8 = col_character(),
#> X9 = col_character(),
#> X10 = col_character()
#> )
#> Warning: 246 parsing failures.
#> row col expected actual file
#> 3 -- 10 columns 9 columns 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
#> 5 -- 10 columns 9 columns 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
#> 7 -- 10 columns 9 columns 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
#> 9 -- 10 columns 9 columns 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
#> 14 -- 10 columns 11 columns 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
#> ... ... .......... .......... ..................................................................................
#> See problems(...) for more details.
auto_df
#> # A tibble: 398 x 10
#> X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
#> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 18 " 8" " 307… " 1… " 3… " 1… " 7… " 1\t\"c… "cheve… "mali…
#> 2 15 " 8" " 350… " 1… " 3… " 1… " 7… " 1\t\"b… "skyla… "320\…
#> 3 18 " 8" " 318… " 1… " 3… " 1… " 7… " 1\t\"p… "satel… <NA>
#> 4 16 " 8" " 304… " 1… " 3… " 1… " 7… " 1\t\"a… "rebel" "sst\…
#> 5 17 " 8" " 302… " 1… " 3… " 1… " 7… " 1\t\"f… "torin… <NA>
#> 6 15 " 8" " 429… " 1… " 4… " 1… " 7… " 1\t\"f… "galax… "500\…
#> 7 14 " 8" " 454… " 2… " 4… " … " 7… " 1\t\"c… "impal… <NA>
#> 8 14 " 8" " 440… " 2… " 4… " … " 7… " 1\t\"p… "fury" "iii\…
#> 9 14 " 8" " 455… " 2… " 4… " 1… " 7… " 1\t\"p… "catal… <NA>
#> 10 15 " 8" " 390… " 1… " 3… " … " 7… " 1\t\"a… "ambas… "dpl\…
#> # … with 388 more rows
mydata <- tibble(my_acc = auto_df$X6, my_horse = auto_df$X4) %>% mutate_all(as.numeric)
#> Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
mydata
#> # A tibble: 398 x 2
#> my_acc my_horse
#> <dbl> <dbl>
#> 1 12 130
#> 2 11.5 165
#> 3 11 150
#> 4 12 150
#> 5 10.5 140
#> 6 10 198
#> 7 9 220
#> 8 8.5 215
#> 9 10 225
#> 10 8.5 190
#> # … with 388 more rows
car_linear_regression <- lm(my_acc ~ my_horse, mydata)
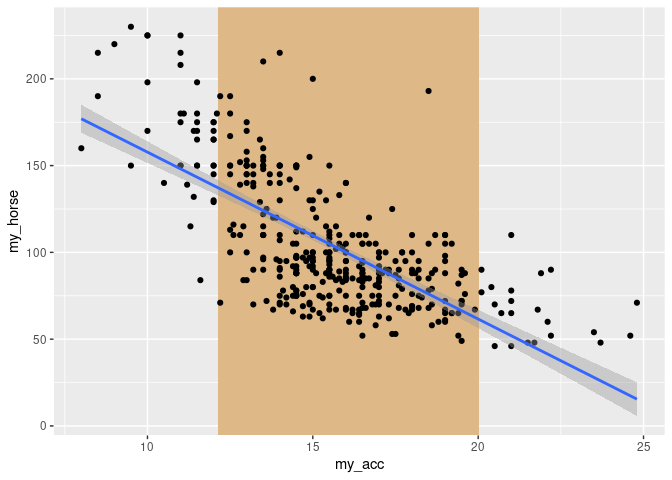
conf_int <- predict(car_linear_regression, newdata = data.frame(my_horse = 93.5), interval = "confidence")
conf_int
#> fit lwr upr
#> 1 16.0832 15.8765 16.28989
pred_int <- predict(car_linear_regression, newdata = data.frame(my_horse = 93.5), interval = "prediction")
pred_int
#> fit lwr upr
#> 1 16.0832 12.14256 20.02383
# ggplot way
ggplot()
geom_rect(
data = pred_int %>% as.data.frame(),
mapping = aes(xmin = lwr, xmax = upr, ymin = -Inf, ymax = Inf),
fill = "BurlyWood"
)
geom_point(
data = mydata,
mapping = aes(my_acc, my_horse)
)
stat_smooth(
data = mydata,
mapping = aes(my_acc, my_horse),
method = "lm"
)
#> `geom_smooth()` using formula 'y ~ x'
#> Warning: Removed 6 rows containing non-finite values (stat_smooth).
#> Warning: Removed 6 rows containing missing values (geom_point).
# Base R way
plot(my_acc ~ my_horse , data = mydata, pch = 20, cex = 1.5, col="blue", xlab=" car horsepower", ylab = "acceleration secs to 100km/h", main = "Confidence intervals and prediction intervals")
rect(min(mydata$my_horse, na.rm = TRUE), pred_int[2], max(mydata$my_horse, na.rm = TRUE), pred_int[3])
abline(car_linear_regression, lwd = 5, col="red" )
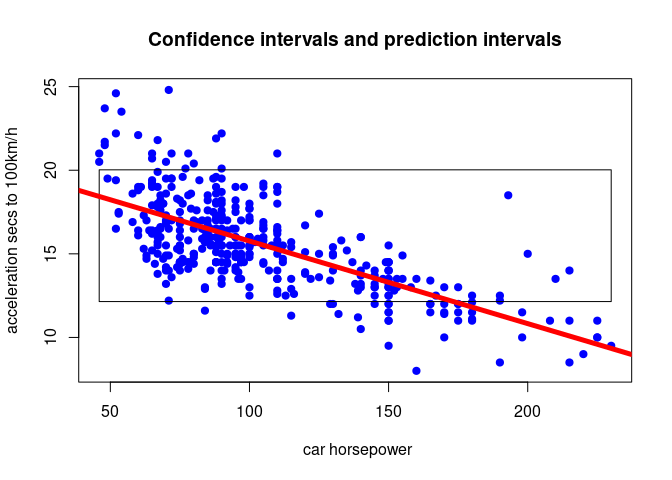
Created on 2021-11-08 by the reprex package (v2.0.1)