Consider the following code, running on an ARM Cortex-A72 processor (optimization guide here). I have included what I expect are resource pressures for each execution port:
| Instruction | B | I0 | I1 | M | L | S | F0 | F1 |
|---|---|---|---|---|---|---|---|---|
.LBB0_1: |
||||||||
ldr q3, [x1], #16 |
0.5 | 0.5 | 1 | |||||
ldr q4, [x2], #16 |
0.5 | 0.5 | 1 | |||||
add x8, x8, #4 |
0.5 | 0.5 | ||||||
cmp x8, #508 |
0.5 | 0.5 | ||||||
mul v5.4s, v3.4s, v4.4s |
2 | |||||||
mul v5.4s, v5.4s, v0.4s |
2 | |||||||
smull v6.2d, v5.2s, v1.2s |
1 | |||||||
smull2 v5.2d, v5.4s, v2.4s |
1 | |||||||
smlal v6.2d, v3.2s, v4.2s |
1 | |||||||
smlal2 v5.2d, v3.4s, v4.4s |
1 | |||||||
uzp2 v3.4s, v6.4s, v5.4s |
1 | |||||||
str q3, [x0], #16 |
0.5 | 0.5 | 1 | |||||
b.lo .LBB0_1 |
1 | |||||||
| Total port pressure | 1 | 2.5 | 2.5 | 0 | 2 | 1 | 8 | 1 |
Although uzp2 could run on either the F0 or F1 ports, I chose to attribute it entirely to F1 due to high pressure on F0 and zero pressure on F1 other than this instruction.
There are no dependencies between loop iterations, other than the loop counter and array pointers; and these should be resolved very quickly, compared to the time taken for the rest of the loop body.
Thus, my intuition is that this code should be throughput limited, and considering the worst pressure is on F0, run in 8 cycles per iteration (unless it hits a decoding bottleneck or cache misses). The latter is unlikely given the streaming access pattern, and the fact that arrays comfortably fit in L1 cache. As for the former, considering the constraints listed on section 4.1 of the optimization manual, I project that the loop body is decodable in only 8 cycles.
Yet microbenchmarking indicates that each iteration of the loop body takes 12.5 cycles on average. If no other plausible explanation exists, I may edit the question including further details about how I benchmarked this code, but I'm fairly certain the difference can't be attributed to benchmarking artifacts alone. Also, I have tried to increase the number of iterations to see if performance improved towards an asymptotic limit due to startup/cool-down effects, but it appears to have done so already for the selected value of 128 iterations displayed above.
Manually unrolling the loop to include two calculations per iteration decreased performance to 13 cycles; however, note that this would also duplicate the number of load and store instructions. Interestingly, if the doubled loads and stores are instead replaced by single LD1/ST1 instructions (two-register format) (e.g. ld1 { v3.4s, v4.4s }, [x1], #32) then performance improves to 11.75 cycles per iteration. Further unrolling the loop to four calculations per iteration, while using the four-register format of LD1/ST1, improves performance to 11.25 cycles per iteration.
In spite of the improvements, the performance is still far away from the 8 cycles per iteration that I expected from looking at resource pressures alone. Even if the CPU made a bad scheduling call and issued uzp2 to F0, revising the resource pressure table would indicate 9 cycles per iteration, still far from actual measurements. So, what's causing this code to run so much slower than expected? What kind of effects am I missing in my analysis?
EDIT: As promised, some more benchmarking details. I run the loop 3 times for warmup, 10 times for say n = 512, and then 10 times for n = 256. I take the minimum cycle count for the n = 512 runs and subtract from the minimum for n = 256. The difference should give me how many cycles it takes to run for n = 256, while canceling out the fixed setup cost (code not shown). In addition, this should ensure all data is in the L1 I and D cache. Measurements are taken by reading the cycle counter (pmccntr_el0) directly. Any overhead should be canceled out by the measurement strategy above.
CodePudding user response:
First off, you can further reduce the theoretical cycles to 6 by replacing the first mul with uzp1 and doing the following smull and smlal the other way around: mul, mul, smull, smlal => smull, uzp1, mul, smlal
This also heavily reduces the register pressure so that we can do an even deeper unrolling (up to 32 per iteration)
And you don't need v2 coefficents, but you can pack them to the higher part of v1
Let's rule out everything by unrolling this deep and writing it in assembly:
.arch armv8-a
.global foo
.text
.balign 64
.func
// void foo(int32_t *pDst, int32_t *pSrc1, int32_t *pSrc2, intptr_t count);
pDst .req x0
pSrc1 .req x1
pSrc2 .req x2
count .req x3
foo:
// initialize coefficients v0 ~ v1
stp d8, d9, [sp, #-16]!
.balign 64
1:
ldp q16, q18, [pSrc1], #32
ldp q17, q19, [pSrc2], #32
ldp q20, q22, [pSrc1], #32
ldp q21, q23, [pSrc2], #32
ldp q24, q26, [pSrc1], #32
ldp q25, q27, [pSrc2], #32
ldp q28, q30, [pSrc1], #32
ldp q29, q31, [pSrc2], #32
smull v2.2d, v17.2s, v16.2s
smull2 v3.2d, v17.4s, v16.4s
smull v4.2d, v19.2s, v18.2s
smull2 v5.2d, v19.4s, v18.4s
smull v6.2d, v21.2s, v20.2s
smull2 v7.2d, v21.4s, v20.4s
smull v8.2d, v23.2s, v22.2s
smull2 v9.2d, v23.4s, v22.4s
smull v16.2d, v25.2s, v24.2s
smull2 v17.2d, v25.4s, v24.4s
smull v18.2d, v27.2s, v26.2s
smull2 v19.2d, v27.4s, v26.4s
smull v20.2d, v29.2s, v28.2s
smull2 v21.2d, v29.4s, v28.4s
smull v22.2d, v31.2s, v20.2s
smull2 v23.2d, v31.4s, v30.4s
uzp1 v24.4s, v2.4s, v3.4s
uzp1 v25.4s, v4.4s, v5.4s
uzp1 v26.4s, v6.4s, v7.4s
uzp1 v27.4s, v8.4s, v9.4s
uzp1 v28.4s, v16.4s, v17.4s
uzp1 v29.4s, v18.4s, v19.4s
uzp1 v30.4s, v20.4s, v21.4s
uzp1 v31.4s, v22.4s, v23.4s
mul v24.4s, v24.4s, v0.4s
mul v25.4s, v25.4s, v0.4s
mul v26.4s, v26.4s, v0.4s
mul v27.4s, v27.4s, v0.4s
mul v28.4s, v28.4s, v0.4s
mul v29.4s, v29.4s, v0.4s
mul v30.4s, v30.4s, v0.4s
mul v31.4s, v31.4s, v0.4s
smlal v2.2d, v24.2s, v1.2s
smlal2 v3.2d, v24.4s, v1.4s
smlal v4.2d, v25.2s, v1.2s
smlal2 v5.2d, v25.4s, v1.4s
smlal v6.2d, v26.2s, v1.2s
smlal2 v7.2d, v26.4s, v1.4s
smlal v8.2d, v27.2s, v1.2s
smlal2 v9.2d, v27.4s, v1.4s
smlal v16.2d, v28.2s, v1.2s
smlal2 v17.2d, v28.4s, v1.4s
smlal v18.2d, v29.2s, v1.2s
smlal2 v19.2d, v29.4s, v1.4s
smlal v20.2d, v30.2s, v1.2s
smlal2 v21.2d, v30.4s, v1.4s
smlal v22.2d, v31.2s, v1.2s
smlal2 v23.2d, v31.4s, v1.4s
uzp2 v24.4s, v2.4s, v3.4s
uzp2 v25.4s, v4.4s, v5.4s
uzp2 v26.4s, v6.4s, v7.4s
uzp2 v27.4s, v8.4s, v9.4s
uzp2 v28.4s, v16.4s, v17.4s
uzp2 v29.4s, v18.4s, v19.4s
uzp2 v30.4s, v20.4s, v21.4s
uzp2 v31.4s, v22.4s, v23.4s
subs count, count, #32
stp q24, q25, [pDst], #32
stp q26, q27, [pDst], #32
stp q28, q29, [pDst], #32
stp q30, q31, [pDst], #32
b.gt 1b
.balign 16
ldp d8, d9, [sp], #16
ret
.endfunc
.end
The code above has zero latency even in-order. The only thing that could affect the performance would be cache miss penalty.
You can measure the cycles, and if it far exceeds 48 per iteration, there must be something wrong with the chip or the document.
Otherwise, the OoO engine of A72 might be lackluster as Peter pointed out.
PS: Or the load/store ports might be not issuing in parallel on A72. This makes sense given your unrolling experiment.
CodePudding user response:
Starting from Jake's code, reducing the unrolling factor by half, changing some of the register allocation, and trying many different variations of load/store instructions (as well as different addressing modes) and instruction scheduling, I finally arrived at the following solution:
ld1 {v16.4s, v17.4s, v18.4s, v19.4s}, [pSrc1], #64
ld1 {v20.4s, v21.4s, v22.4s, v23.4s}, [pSrc2], #64
add count, pDst, count, lsl #2
// initialize v0/v1
loop:
smull v24.2d, v20.2s, v16.2s
smull2 v25.2d, v20.4s, v16.4s
uzp1 v2.4s, v24.4s, v25.4s
smull v26.2d, v21.2s, v17.2s
smull2 v27.2d, v21.4s, v17.4s
uzp1 v3.4s, v26.4s, v27.4s
smull v28.2d, v22.2s, v18.2s
smull2 v29.2d, v22.4s, v18.4s
uzp1 v4.4s, v28.4s, v29.4s
smull v30.2d, v23.2s, v19.2s
smull2 v31.2d, v23.4s, v19.4s
uzp1 v5.4s, v30.4s, v31.4s
mul v2.4s, v2.4s, v0.4s
ldp q16, q17, [pSrc1]
mul v3.4s, v3.4s, v0.4s
ldp q18, q19, [pSrc1, #32]
add pSrc1, pSrc1, #64
mul v4.4s, v4.4s, v0.4s
ldp q20, q21, [pSrc2]
mul v5.4s, v5.4s, v0.4s
ldp q22, q23, [pSrc2, #32]
add pSrc2, pSrc2, #64
smlal v24.2d, v2.2s, v1.2s
smlal2 v25.2d, v2.4s, v1.4s
uzp2 v2.4s, v24.4s, v25.4s
str q24, [pDst], #16
smlal v26.2d, v3.2s, v1.2s
smlal2 v27.2d, v3.4s, v1.4s
uzp2 v3.4s, v26.4s, v27.4s
str q25, [pDst], #16
smlal v28.2d, v4.2s, v1.2s
smlal2 v29.2d, v4.4s, v1.4s
uzp2 v4.4s, v28.4s, v29.4s
str q26, [pDst], #16
smlal v30.2d, v5.2s, v1.2s
smlal2 v31.2d, v5.4s, v1.4s
uzp2 v5.4s, v30.4s, v31.4s
str q27, [pDst], #16
cmp count, pDst
b.ne loop
Note that, although I have carefully reviewed the code, I haven't tested whether it actually works, so there may be something missing that would impact performance. A final iteration of the loop, removing the load insructions, is required to prevent an out-of-bounds memory access; I omitted this to save some space.
Performing a similar analysis as to that of the original question, assuming the code is fully throughput-limited, would suggest that this loop would take 24 cycles. Normalizing to the same metric as used elsewhere (i.e. cycles per 4-element iteration), this would work out to 6 cycles/iteration. Benchmarking the code resulting in 26 cycles per loop execution, or in the normalized metric, 6.5 cycles/iteration. While not the bare minimum supposedly achievable, it comes very close to this.
Some notes for anyone else who stumbles across this question, after scratching their heads about Cortex-A72 performance:
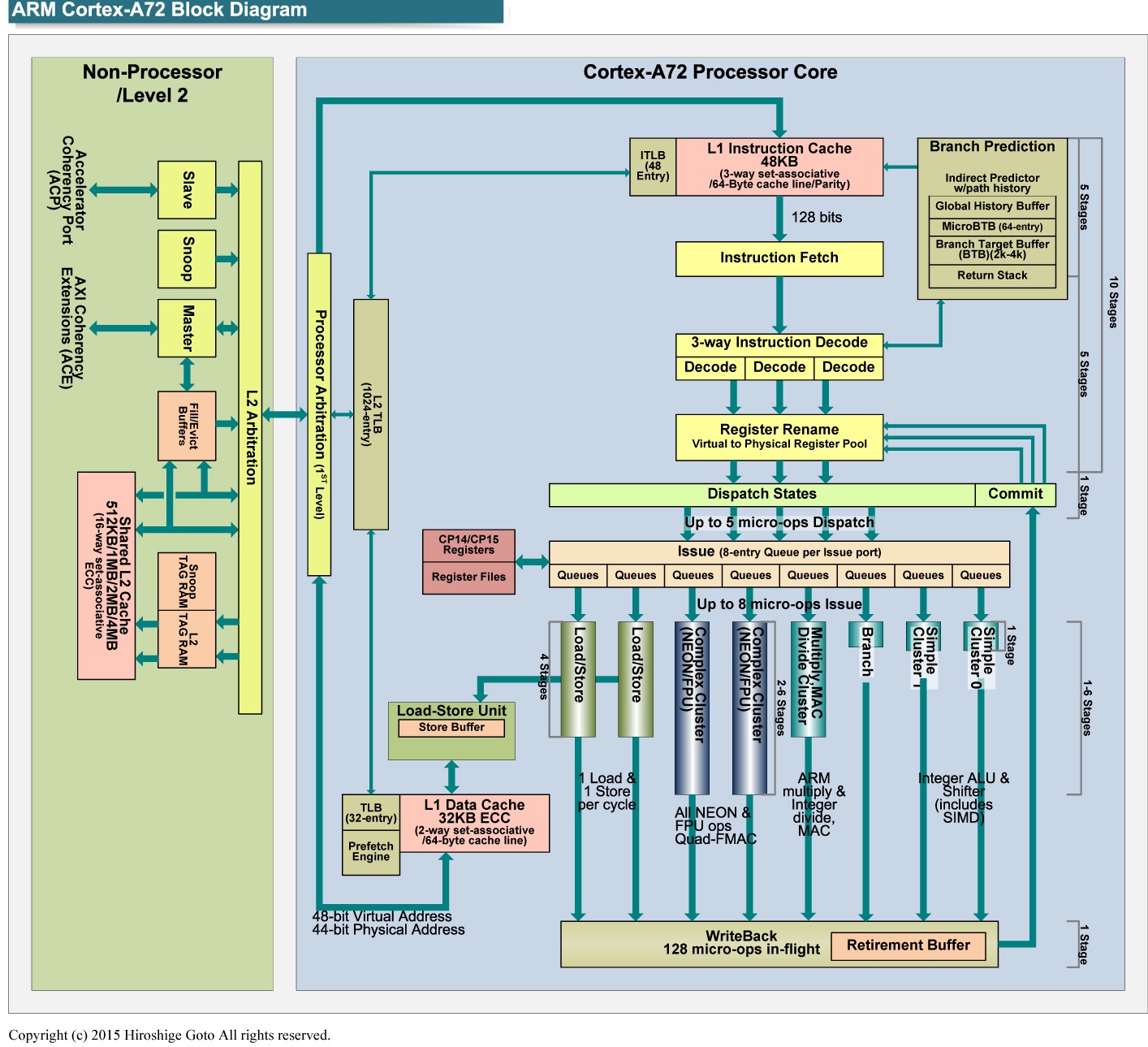
The schedulers (reservation stations) are per-port rather than global (see this article and this block diagram). Unless your code has a very balanced instruction mix among loads, stores, scalar, Neon, branches, etc., then the OoO window will be smaller than you would expect, sometimes very much so. This code in particular is a pathological case for per-port schedulers. since 70% of all instructions are Neon, and 50% of all instructions are multiplications (which only run on the F0 port). For these multiplications, the OoO window is a very anemic 8 instructions, so don't expect the CPU to be looking at the next loop iteration's instructions while executing the current iteration.
Attempting to further reduce the unrolling factor by half results in a large (23%) slowdown. My guess for the cause is the shallow OoO window, due to the per-port schedulers and the high prevalence of instructions bound to port F0, as explained in point 1 above. Without being able to look at the next iteration, there is less parallelism to be extracted, so the code becomes latency- rather than throughput-bound. Thus, it appears that interleaving multiple iterations of a loop is an important optimization strategy to consider for this core.
One must pay attention to the specific addressing mode used for loads. Replacing the immediate post-index addressing mode used in the original code with immediate offset, and then manually performing incrementing the pointers elsewhere, resulted in performance gains, but only for the loads (stores were unaffected). In section 4.5 ("Load/Store Throughput") of the optimization manual, this is hinted in the context of a memory copy routine, but no rationale is given. However, I believe this is explained by point 4 below.
Apparently the main bottleneck of this code is writing to the register file: according to this answer to another SO question, the register file only supports writing 192 bits per cycle. This may explain why loads should avoid the use of addressing modes with writeback (pre- and post-index), as this consumes an extra 64 bits writing the result back to the register file. It's all too easy to exceed this limit while using Neon instructions and vector loads (even more so when using
LDPand 2/3/4-register versions ofLD1), without the added pressure of writing back the incremented address. Knowing this, I also decide to replace the originalsubsin Jake's code with a comparison topDst, since comparisons don't write to the register file -- and this actually improved performance by 1/4 of a cycle.
{kind=link}
Interestingly, adding up the number of bits written to the register file during one execution of the loop results in 4992 bits (I have no idea whether writes to PC, specifically by the b.ne instruction, should be included in the tally or not; I arbitrarily chose not to). Given the 192-bit/cycle limit, this works out to a minimum of 26 cycles to write all these results to the register file across the loop. So it appears that the code above can't be made faster by rescheduling instructions alone.
Theoretically it might be possible to shed 1 cycle by switching the addressing mode of the stores to immediate offset, and then including an extra instruction to explicitly increment pDst. For the original code, each of the 4 stores would write 64 bits to pDst, for a total of 256 bits, compared to a single 64-bit write if pDst were explicitly incremented once. Thus, this change would result in saving 192 bits, i.e., 1 cycle's worth of register file writes. I attempted this change, trying to schedule the increments of pSrc1/pSrc2/pDst across many different points of the code, but unfortunately I was only able to slow down rather than speed up the code. Perhaps I am hitting a different bottleneck such as instruction decoding.