I am working on a project to web-scrap large volumes of data daily and input them into a database. I have been attempting to do it as methodically as possible. I was able to create a parse function that was able to extract data from multiple pages. However, when I added a parse item function I kept failing. I have gone over the Scrapy documentation and tried to follow it as best as possible but to no avail.
I have been stuck for a few days and wanted to ask the Stack Overflow community for assistance. I apologize if my question is really long. I have been so confused that I wanted to see if I could get a thorough explanation/guidance, rather than keep posting question after question for each and every problem I encountered. I just want to make my project as efficient and well-done as possible. Any and all help is greatly appreciated. Thank you^^
Full Code:
import scrapy
from scrapy import Request
from datetime import datetime
from scrapy.crawler import CrawlerProcess
dt_today = datetime.now().strftime('%Y%m%d')
file_name = dt_today ' HPI Data'
# Create Spider class
class UneguiApartments(scrapy.Spider):
name = 'unegui_apts'
allowed_domains = ['www.unegui.mn']
custom_settings = {'FEEDS': {f'{file_name}.csv': {'format': 'csv'}},
'USER_AGENT': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"}
start_urls = [
'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/'
]
def parse(self, response):
cards = response.xpath('//li[contains(@class,"announcement-container")]')
for card in cards:
name = card.xpath(".//a[@itemprop='name']/@content").extract_first()
price = card.xpath(".//*[@itemprop='price']/@content").extract_first()
date_block = card.xpath("normalize-space(.//div[contains(@class,'announcement-block__date')]/text())").extract_first().split(',')
date = date_block[0].strip()
city = date_block[1].strip()
link = card.xpath(".//a[@itemprop='url']/@href").extract_first()
yield Request(link, callback=self.parse_item)
yield {'name': name,
'price': price,
'date': date,
'city': city,
'link': 'https://www.unegui.mn' link
}
def parse_item(self, response):
# extract things from the listinsg item page
spanlist = response.xpath('.//span[contains(@class, )]//text()').extract()
alist = response.xpath(".//a[@itemprop='url']/@href").extract()
list_item1 = spanlist[0].strip()
list_item2 = spanlist[1].strip()
list_item3 = alist[0].strip()
list_item4 = alist[1].strip()
yield {'item1': list_item1,
'item2': list_item2,
'item3': list_item3,
'item4':list_item4
}
next_url = response.xpath(
"//a[contains(@class,'red')]/parent::li/following-sibling::li/a/@href").extract_first()
if next_url:
# go to next page until no more pages
yield response.follow(next_url, callback=self.parse)
# main driver
if __name__ == "__main__":
process = CrawlerProcess()
process.crawl(UneguiApartments)
process.start()
Current Results:
Run logs: 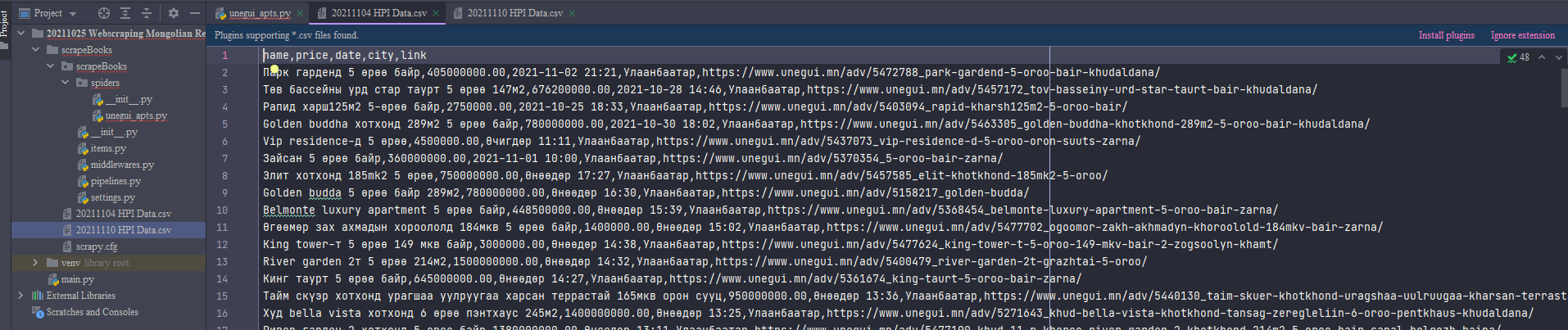
Item Picture Snippet:

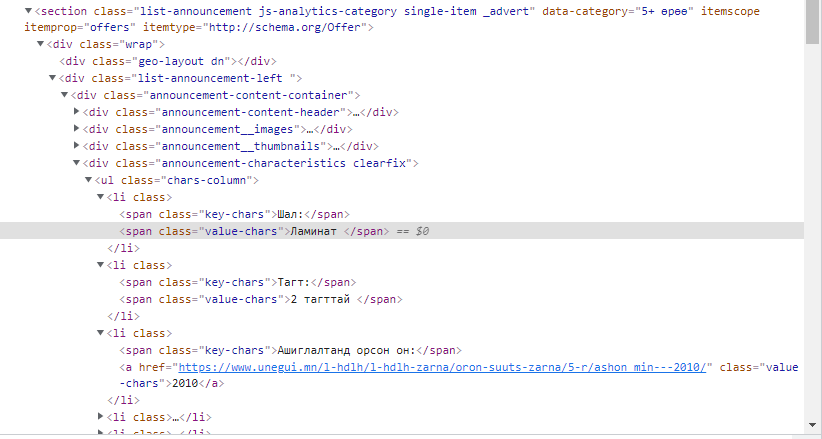
Item HTML Snippet:
Sidenote if anyone has the time or interest to guide me further. In the future I am planning to add to my code so I can:
- Use something like selenium to be able to scrape dynamic pages (e.g. be able to click on a button that reveals text/data, and then be able to scrape that).
- Clean, transform, and normalize the scraped data.
- Add to a DBeaver database.
- Check and remove duplicates so there is only 1 unique apartment listing in the database.
- Run a scheduled web scraper once a day automatically.
Hopefully, I want to scrape all categories of data from https://www.unegui.mn using scraps and make a spider for each category. The website has ~94,000 listings. Once completed, ideally I want to add a few more different websites to get additional advertisement listings.
Currently, I am scraping and outputting as a CSV file. Ideally, I want to be able to not only output as a CSV file on choice but to upload my data directly to a DBeaver database. I understand this is a large undertaking, but I really want to make a complex and diverse scrapy code that can be used to collect a large volume of data daily. Is this too ambitious? Once again, thank you for any and all input, and I apologize for the long post.
Questions:
- Is it better to use one spider for each category from one website, or one spider per website?
- Should I put all my web listings scraping code into one project folder or split them up?
- Is there a naming convention I should follow?
- Will using ItemLoader() and Input and Output make my code more efficient and faster? If not, taking into consideration my future additions, what path/method should I implement?
- Are there any other methods or conventions I should follow to make my code as efficient and well-structured as possible?
CodePudding user response:
Taking a look at your logs there seems to be an error:
raise ValueError(f'Missing scheme in request url: {self._url}')
ValueError: Missing scheme in request url: /adv/5040771_belmonte/
I suspect this line is faulty as it might yield a request to a relative url where's Scrapy's Request objects always expect the url to be absolute:
cards = response.xpath('//li[contains(@class,"announcement-container")]')
for card in cards:
name = card.xpath(".//a[@itemprop='name']/@content").extract_first()
price = card.xpath(".//*[@itemprop='price']/@content").extract_first()
date_block = card.xpath("normalize-space(.//div[contains(@class,'announcement-block__date')]/text())").extract_first().split(',')
date = date_block[0].strip()
city = date_block[1].strip()
link = card.xpath(".//a[@itemprop='url']/@href").extract_first()
yield Request(link, callback=self.parse_item)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
yield {'name': name,
'price': price,
'date': date,
'city': city,
'link': 'https://www.unegui.mn' link
}
The link variable here can be a relative link (like the one mentioned in your lgos /adv/5040771_belmonte.
To fix this either urljoin expliclitly:
yield Request(response.urljoin(link), callback=self.parse_item)
or use response.follow shortcut:
yield response.follow(link, callback=self.parse_item)
Further you should use item carry-over between your callbacks:
def parse(self, response):
cards = response.xpath('//li[contains(@class,"announcement-container")]')
for card in cards:
# ...
item = {'name': name,
'price': price,
'date': date,
'city': city,
'link': 'https://www.unegui.mn' link
}
yield response.follow(link, callback=self.parse_item, meta={"item": item})
def parse_item(self, response):
# retrieve previously scraped item
item = response.meta['item']
# ... parse additional details
item.update({'item1': list_item1,
'item2': list_item2,
'item3': list_item3,
'item4':list_item4
})
yield item
# ... next url