I have an interesting situation in SQL Server 2016. I am using T-SQL language.
I have a dataset called (#dataset):
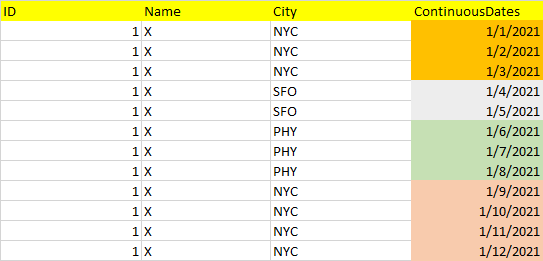
The last column called ContinuousDates will ALWAYS have continuous date values without a gap, say Jan 1, 2021 to Dec 31, 2021. It will NEVER have duplicate dates for the same ID or Name, i.e. one person on a given day can have only one row of data. (In this example, I am showing just one person, with ID = 1 and Name = X. In my actual data, I have multiple people).
Note that NYC city occurs earlier in the dataset, and gets repeated in the last 4 rows.
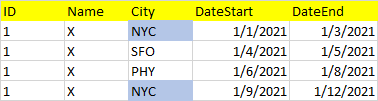
I need to obtain the below dataset based on date range:
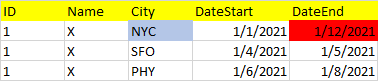
I tried to use a simple MINIMUM and MAXIMUM on the dataset, but I realize that at times I can get a wrong output, as below:
I tried some options using RANK() and DENSE_RANK() functions, but am not able to come to a solution. Can someone provide me assistance ?
I have the codes attached here:
CREATE TABLE #dataset
(
ID int,
Name varchar(20),
City varchar(20),
ContinuousDates date
)
INSERT INTO #dataset
VALUES(1,'X','NYC','1/1/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/2/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/3/2021')
INSERT INTO #dataset
VALUES(1,'X','SFO','1/4/2021')
INSERT INTO #dataset
VALUES(1,'X','SFO','1/5/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/6/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/7/2021')
INSERT INTO #dataset
VALUES(1,'X','PHY','1/8/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/9/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/10/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/11/2021')
INSERT INTO #dataset
VALUES(1,'X','NYC','1/12/2021')
SELECT *
FROM #dataset
ORDER BY ContinuousDates
CodePudding user response:
This is a type of gaps-and-islands problem.
There are a number of different solutions. Here is one simple one
- Use
LAGto identify rows that start each island - A running conditional count gives us an ID for each island
- Then simply group up by that ID (along with any other partition columns)
WITH StartPoints AS (
SELECT *,
IsStart = CASE WHEN LAG(City, 1, '') OVER (PARTITION BY ID ORDER BY ContinuousDates)
<> City THEN 1 END
FROM #dataset ds
),
Groups AS (
SELECT *,
GroupId = COUNT(IsStart) OVER (PARTITION BY ID ORDER BY ContinuousDates ROWS UNBOUNDED PRECEDING)
FROM StartPoints
)
SELECT
ID,
Name,
City = MIN(City),
DateStart = MIN(ContinuousDates),
DateEnd = MAX(ContinuousDates)
FROM Groups
GROUP BY
ID,
Name,
GroupId;
CodePudding user response:
Solution steps:
- numbers all rows sorted by date (row_id)
- numbers sections with unique ID, Name and City sorted by date (p_row_id)
- calculate row_id - p_row_id
Now you have group numbers for each period within unique set of values.
All that you need is to group by this number, ID, Name and City
| ID | Name | City | ContinuousDates | p_row_id | row_id | row_id - p_row_id |
|---|---|---|---|---|---|---|
| 1 | X | NYC | 2021-01-01 | 1 | 1 | 0 |
| 1 | X | NYC | 2021-01-02 | 2 | 2 | 0 |
| 1 | X | NYC | 2021-01-03 | 3 | 3 | 0 |
| 1 | X | SFO | 2021-01-04 | 1 | 4 | 3 |
| 1 | X | SFO | 2021-01-05 | 2 | 5 | 3 |
| 1 | X | PHY | 2021-01-06 | 1 | 6 | 5 |
| 1 | X | PHY | 2021-01-07 | 2 | 7 | 5 |
| 1 | X | PHY | 2021-01-08 | 3 | 8 | 5 |
| 1 | X | NYC | 2021-01-09 | 4 | 9 | 5 |
| 1 | X | NYC | 2021-01-10 | 5 | 10 | 5 |
| 1 | X | NYC | 2021-01-11 | 6 | 11 | 5 |
| 1 | X | NYC | 2021-01-12 | 7 | 12 | 5 |
select
CD.ID
,CD.[Name]
,CD.City
,min(CD.ContinuousDates) as DateStart
,max(CD.ContinuousDates) as DateEnd
from
(
select *
,row_number() over(partition by CD.ID, [Name], CD.City order by CD.ContinuousDates) as p_row_id
,row_number() over(order by CD.ContinuousDates) as row_id
from #dataset CD
) CD
group by CD.row_id - CD.p_row_id
,CD.ID
,CD.[Name]
,CD.City
order by DateStart