I'm struggling with an Pyspark Dataframe containing information on a meeting with every single word spoken represented as a row. I like to group those words spoken by each person until the other person starts talking. (There are just two person speaking)
I already tried some window functions, but never were able to reach the desired output. Would be happy for any help!
Input:
| Call_id| Speaker | WordNum| Word |
|------- |----------| -------|------|
| 1 | Speaker_1| 1 |Hi |
| 1 | Speaker_1| 2 |I |
| 1 | Speaker_1| 3 |am |
| 1 | Speaker_1| 4 |Pete |
| 1 | Speaker_2| 5 |Hello |
| 1 | Speaker_1| 6 |Sorry |
| 1 | Speaker_1| 7 |Gotta |
| 1 | Speaker_1| 8 |Leave |
| 2 | Speaker_2| 1 |Hello |
| 2 | Speaker_2| 2 |Luis |
| 2 | Speaker_1| 3 |Hey |
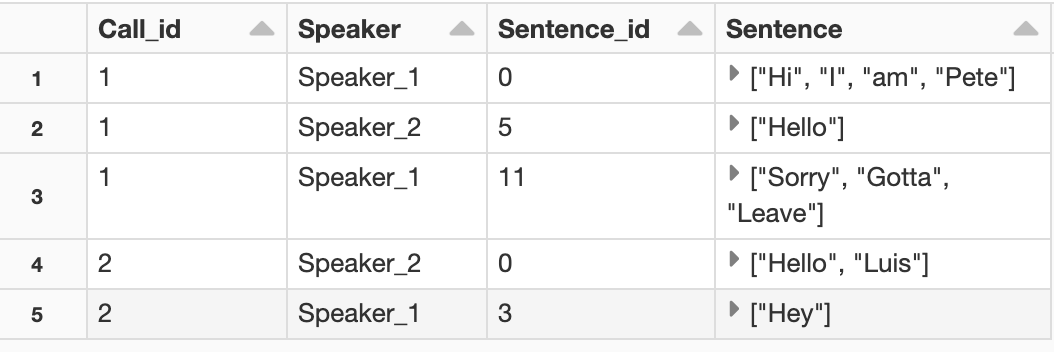
Desired Output:
| Call_id| Speaker | Sentence |
|------- |----------| ----------------------------|
| 1 | Speaker_1| ["Hi", "I", "am", "Pete"] |
| 1 | Speaker_2| ["Hello"] |
| 1 | Speaker_1| ["Sorry", "Gotta", "Leave"] |
| 2 | Speaker_2| ["Hello", "Luis"] |
| 2 | Speaker_1| ["Hey"] |
CodePudding user response:
You can create sentence id, and then group by call id, speaker, and sentence id and collect words. To create sentence id - check when speaker value is changing by comparing current and previous values. Create indicator column so that if speaker has changed, use word number as identifier,otherwise 0. After that, cumsum this indicator will work as the sentence id.
import pyspark.sql.functions as F
from pyspark.sql import Window
# 1 create speaker lag column and fill in NAs with current speaker info
w = Window.partitionBy("Call_id").orderBy("WordNum")
df1 = (df
.withColumn("speaker_lag", F.lag("Speaker").over(w))
.withColumn("speaker_lag1", F.coalesce("speaker_lag", "Speaker")))
# 2 create sentence indicator
df2 = (df1
.withColumn("session",
F.when(F.col("Speaker")==F.col("speaker_lag1"), 0)
.otherwise(F.col("WordNum"))))
# create sentence id
w = (Window
.partitionBy("Call_id")
.orderBy("WordNum")
.rangeBetween(Window.unboundedPreceding, 0))
df3 = df2.withColumn("Sentence_id", F.sum("session").over(w))
# group by and collect
df4 = (df3
.groupBy("Call_id", "Speaker", "Sentence_id")
.agg(F.sort_array(F.collect_list(F.struct("WordNum", "Word")))
.alias("collect"))
.withColumn("Sentence", F.col("collect")["Word"])
.select("Call_id", "Speaker", "Sentence_id", "Sentence")
)
For your data input:
cols = ["Call_id", "Speaker", "WordNum", "Word"]
data = [
( 1 , "Speaker_1", 1 ,"Hi" ),
( 1 , "Speaker_1", 2 ,"I" ),
( 1 , "Speaker_1", 3 ,"am" ),
( 1 , "Speaker_1", 4 ,"Pete" ),
( 1 , "Speaker_2", 5 ,"Hello" ),
( 1 , "Speaker_1", 6 ,"Sorry" ),
( 1 , "Speaker_1", 7 ,"Gotta" ),
( 1 , "Speaker_1", 8 ,"Leave" ),
( 2 , "Speaker_2", 1 ,"Hello" ),
( 2 , "Speaker_2", 2 ,"Luis" ),
( 2 , "Speaker_1", 3 ,"Hey" )]
df = spark.createDataFrame(data, schema=cols)
the output df4 will be