I am trying to extract 2 sets of data from: "https://www.kucoin.com/news/categories/listing" using a python script and drop it into a list or dictionary. I've tried Selenium and BeautifulSoup as well as request. All of them return an empty: [] or None. I've been at this all day with no success. I have tried to use the full xpath as well to try to index the location of the text, which had the same result. Any help at this point would be much appreciated.
##########################################################
from bs4 import BeautifulSoup
import requests
url = requests.get('https://www.kucoin.com/news/categories/listing')
soup = BeautifulSoup(url.text, features="lxml")
listing = soup.find(class_='mainTitle___mbpq1')
print(listing)
###########################################################
import requests
from lxml import html
def main():
url = "https://www.kucoin.com/news/categories/listing"
page = requests.get(url)
tree = html.fromstring(page.content)
text_val = tree.xpath('//div[@]')
print(text_val)
###########################################################
CodePudding user response:
I checked the response from the request.get method and saw that the initial source code is plain javascript. You have to wait for its execution to finish to parse the final rendered html. If you are fine with using selenium as you have tried with that, here is a solution I came up with to get the first element. Adjust the timeout based on your internet connection speed
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("https://www.kucoin.com/news/categories/listing")
try:
elem = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CLASS_NAME, "info___1vA3W"))
)
title = elem.find_element_by_tag_name("a")
date_desc = elem.find_element_by_tag_name("p")
title_text = title.text
date_text = date_desc.text
print(title_text, date_text)
finally:
driver.quit()
CodePudding user response:
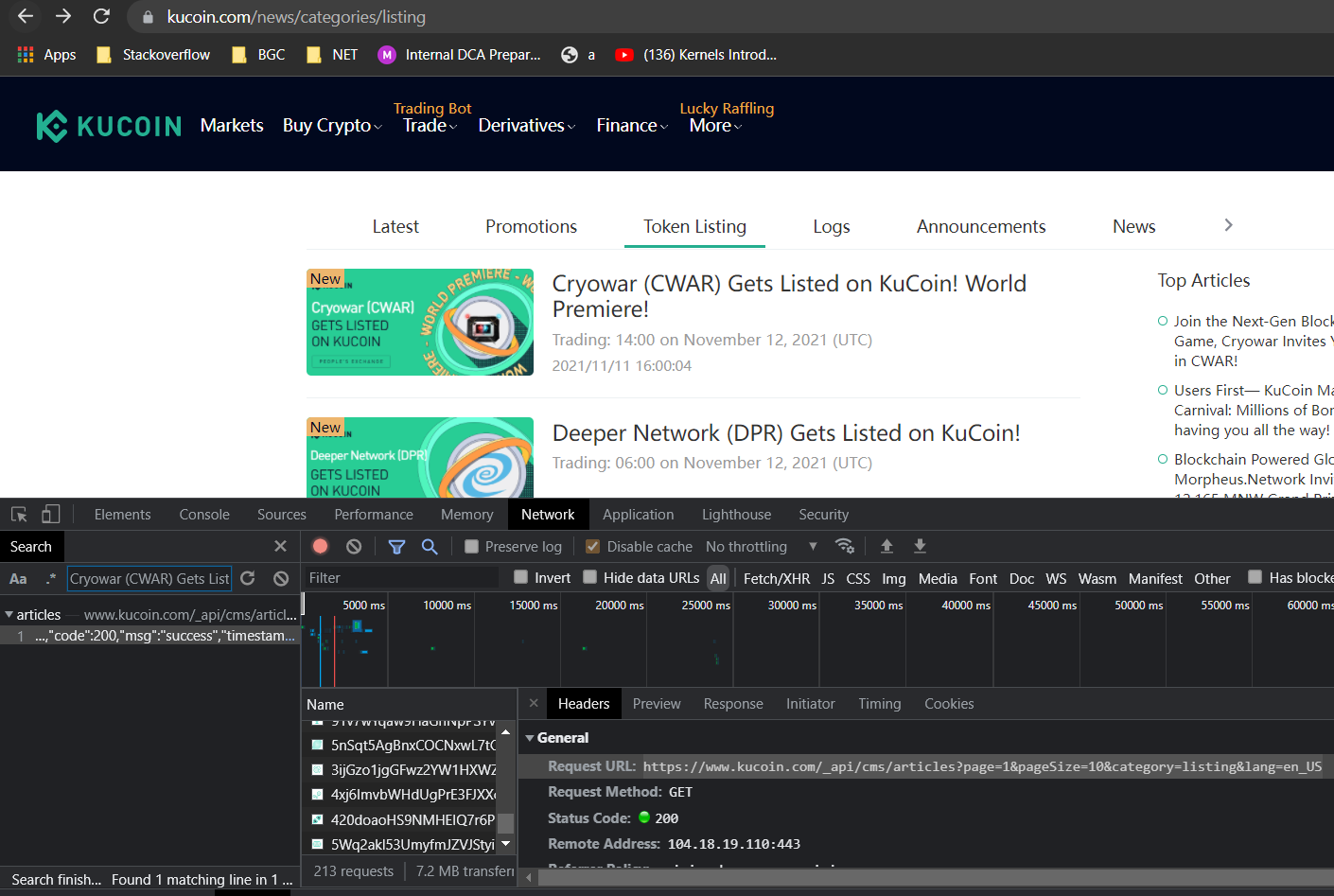
As already explained, the data is loaded by an API. You can use the same to extract the details using requests.
Have only tried for page 1.
import requests
response = requests.get("https://www.kucoin.com/_api/cms/articles?page=1&pageSize=10&category=listing&lang=en_US")
jsoncode = response.json()
options = jsoncode['items']
for i in range(len(options)):
title = options[i]['title']
date = options[i]['summary']
print(f"{title} : {date}")
Cryowar (CWAR) Gets Listed on KuCoin! World Premiere! : Trading: 14:00 on November 12, 2021 (UTC)
Deeper Network (DPR) Gets Listed on KuCoin! : Trading: 06:00 on November 12, 2021 (UTC)
Vectorspace AI (VXV) Gets Listed on KuCoin! : Trading: 8:00 on November 12, 2021 (UTC)
...