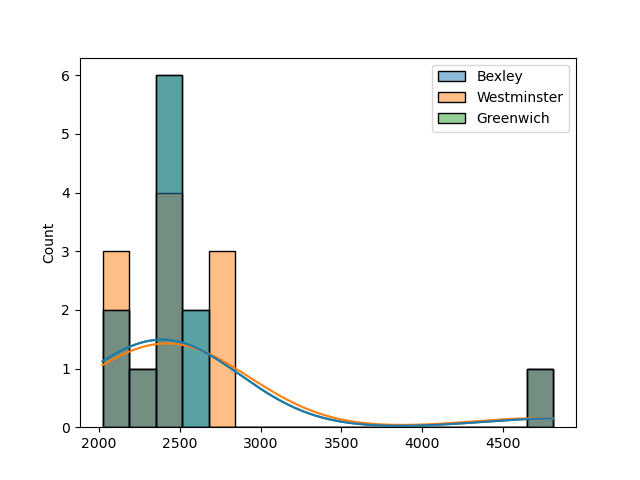
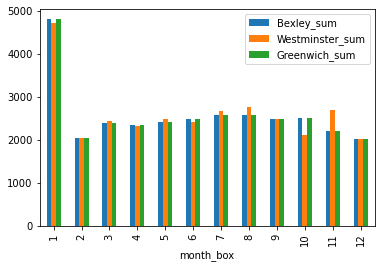
I have three dataframes in the format below, which have a column with the month of the year in digit format, and a column adjacent to it which has the number of items occurring in that month. I wanted to create an overlapping histogram detailing the spread between the three histograms but for some reason I keep getting the same thing!
month_box Sum Value
0 1 4812
1 2 2053
2 3 2405
3 4 2353
4 5 2427
5 6 2484
6 8 2579
7 9 2580
8 10 2497
9 11 2510
10 12 2202
The code I am using is below:
sns.distplot(bex_boxdf['month_box'],kde=False,label = 'Bexley')
sns.distplot(west_boxdf['month_box'],kde=False,label = 'Westminster')
sns.distplot(gwch_boxdf['month_box'],kde=False,label = 'Greenwich')
plt.legend(prop={'size': 12})
plt.title('Crime by month')
plt.xlabel('Month')
plt.ylabel('Density')
I attach below the result I get...help would be appreciated thank you.
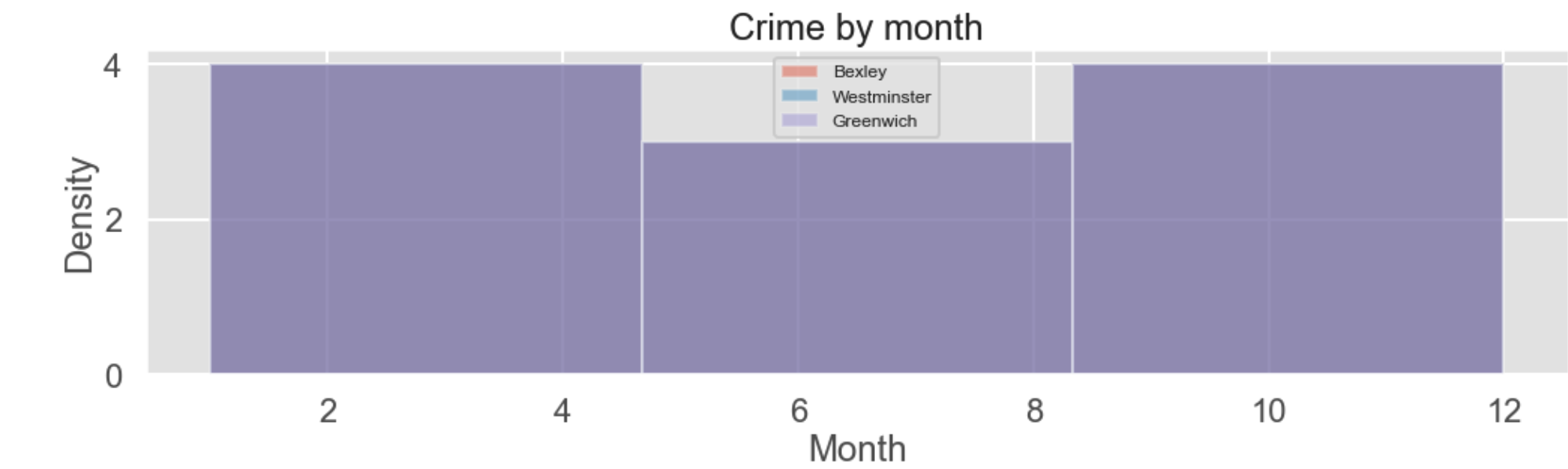
CodePudding user response:
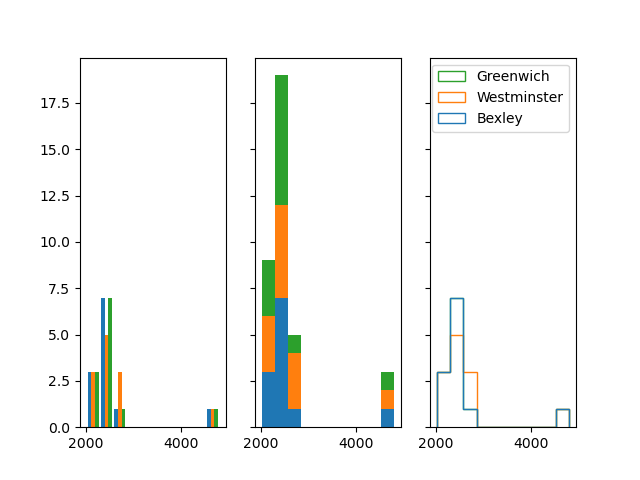
Histograms using Matplotlib
Here are three different views using the data provided by @Esa.
There is also a 'stepfilled' histogram type that I didn't include but could be useful depending on the distribution of the data:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({'month_box': [1,2,3,4,5,6,7,8,9,10,11,12],
'Bexley': [4812,2053,2405,2353,2427,2484,2579,2580,
2497,2510,2202,2021],
'Westminster': [4712,2050,2435,2323,2487,2414,2679,2780,
2490,2110,2702,2022],
'Greenwich': [4812,2053,2405,2353,2427,2484,2579,2580,
2497,2510,2202,2021],
})
data = df["Bexley"], df["Westminster"], df["Greenwich"]
labels = ["Bexley", "Westminster", "Greenwich"]
fig, ax = plt.subplots(ncols=3, sharex=True, sharey=True)
ax[0].hist(x=data, histtype="bar",label=labels)
ax[1].hist(x=data, histtype="barstacked",label=labels)
ax[2].hist(x=data, histtype="step", label=labels)
plt.legend()
plt.show()
Matplotlib has a lot of customization options. Referring to the documentation could be useful.