I would like to calculate the number of people (dataframe variable) for a sector (ROME column) belonging to a workgroup (FAP column) for each year that I divide by the total number of people in that workgroup.
The total number of workgroups is stored in a variable Total_FAP :
Total_FAP = df2.Total
Total_FAP.head()
which shows
FAP
Agents administratifs et commerciaux des transports et du tourisme 63160.0
Agents d'entretien 718150.0
Agents d'exploitation des transports 142680.0
Agents de gardiennage et de sécurité 465010.0
Agriculteurs, éleveurs, sylviculteurs, bûcherons 121040.0
For example, for the year 2010, I have to take the number of people for the ROME A1101 corresponding to the FAP "Agriculteurs, éleveurs, sylviculteurs, bûcherons " (which is 2630) and divide it by the total number that is in the pandas series (which is 121040). It would make something like : 2630/121040 = 0.02172835426
I would like to know if there is a way to make a function, because I wanted to try to make an iteration on the dataframes but I saw that it was not advised....
Thanks for your help
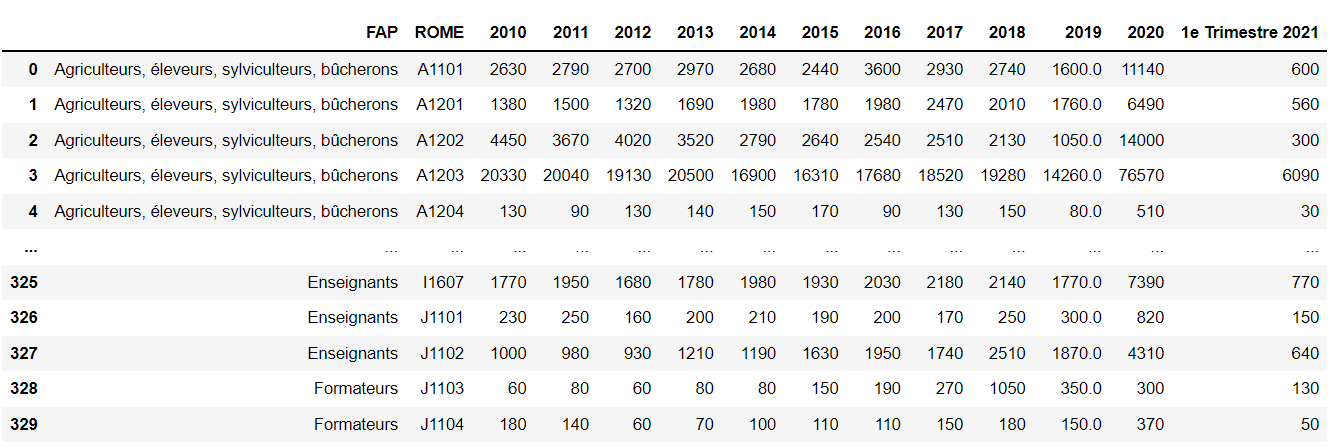
EDIT: Here is the raw data for DF1
{'FAP': {0: 'Agriculteurs, éleveurs, sylviculteurs, bûcherons',
1: 'Agriculteurs, éleveurs, sylviculteurs, bûcherons',
2: 'Agriculteurs, éleveurs, sylviculteurs, bûcherons',
3: 'Agriculteurs, éleveurs, sylviculteurs, bûcherons',
4: 'Agriculteurs, éleveurs, sylviculteurs, bûcherons'},
'ROME': {0: 'A1101', 1: 'A1201', 2: 'A1202', 3: 'A1203', 4: 'A1204'},
'2010': {0: 2630, 1: 1380, 2: 4450, 3: 20330, 4: 130},
'2011': {0: 2790, 1: 1500, 2: 3670, 3: 20040, 4: 90},
'2012': {0: 2700, 1: 1320, 2: 4020, 3: 19130, 4: 130},
'2013': {0: 2970, 1: 1690, 2: 3520, 3: 20500, 4: 140},
'2014': {0: 2680, 1: 1980, 2: 2790, 3: 16900, 4: 150},
'2015': {0: 2440, 1: 1780, 2: 2640, 3: 16310, 4: 170},
'2016': {0: 3600, 1: 1980, 2: 2540, 3: 17680, 4: 90},
'2017': {0: 2930, 1: 2470, 2: 2510, 3: 18520, 4: 130},
'2018': {0: 2740, 1: 2010, 2: 2130, 3: 19280, 4: 150},
'2019': {0: 1600.0, 1: 1760.0, 2: 1050.0, 3: 14260.0, 4: 80.0},
'2020': {0: 11140, 1: 6490, 2: 14000, 3: 76570, 4: 510},
'1e Trimestre 2021': {0: 600, 1: 560, 2: 300, 3: 6090, 4: 30}}
CodePudding user response:
You could use:
cols = df.filter(regex='^\d{4}$').columns
df = df.merge(Total_FAP, left_on='FAP', right_index=True, suffixes=('', '_total'))
df[cols].div(df['FAP_total'], axis=0)
output:
2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020
0 0.021728 0.023050 0.022307 0.024537 0.022141 0.020159 0.029742 0.024207 0.022637 0.013219 0.092036
1 0.011401 0.012393 0.010905 0.013962 0.016358 0.014706 0.016358 0.020406 0.016606 0.014541 0.053619
2 0.036765 0.030321 0.033212 0.029081 0.023050 0.021811 0.020985 0.020737 0.017597 0.008675 0.115664
3 0.167961 0.165565 0.158047 0.169365 0.139623 0.134749 0.146067 0.153007 0.159286 0.117812 0.632601
4 0.001074 0.000744 0.001074 0.001157 0.001239 0.001404 0.000744 0.001074 0.001239 0.000661 0.004213