Absolute newbie to R. I have a dataframe that has some common values in one column(C1), but only one of the corresponding column has a value(C2), so I want to paste that value to all of the empty/NA spaces in C2 based on same value in C1. This would make more sense:
df:
C1 C2
A NA
A val10
A NA
B val14
B NA
B NA
B NA
C NA
C val9
What I wanted it to look like is
C1 C2
A val10
A val10
A val10
B val14
B val14
B val14
B val14
C val9
C val9
(C2 and C1 don't have any particular pattern or sequence between each other)
I'm assuming I would do a Group_by for C1, but I'm bit confused how to copy the values. Using transmute/mutate or paste. I tried a few iterations but wasn't successful.
CodePudding user response:
You can use the fill function from tidyr, which makes it really easy to take care of the NAs.
library(tidyr)
library(dplyr)
df %>%
dplyr::group_by(C1) %>%
tidyr::fill(C2) %>% #default direction down
tidyr::fill(C2, .direction = "up")
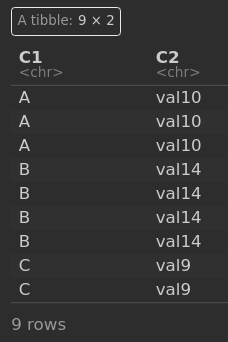
Output
# A tibble: 9 × 2
# Groups: C1 [3]
C1 C2
<chr> <chr>
1 A val10
2 A val10
3 A val10
4 B val14
5 B val14
6 B val14
7 B val14
8 C val9
9 C val9
Data
df <- structure(list(C1 = c("A", "A", "A", "B", "B", "B", "B", "C",
"C"), C2 = c(NA, "val10", NA, "val14", NA, NA, NA, NA, "val9"
)), class = "data.frame", row.names = c(NA, -9L))
CodePudding user response:
I doubt this is the most elegant solution, but a Tidyverse-style method could be:
df <- tibble::tribble(
~C1, ~C2,
"A", NA,
"A", "val10",
"A", NA,
"B", "val14",
"B", NA,
"B", NA,
"B", NA,
"C", NA,
"C", "val9"
)
df %>%
filter(!is.na(C2)) %>%
rename(C3 = C2) %>%
right_join(df) %>%
select(-C2) %>%
rename(C2 = C3)
Which gives you: