I am using this dataset: 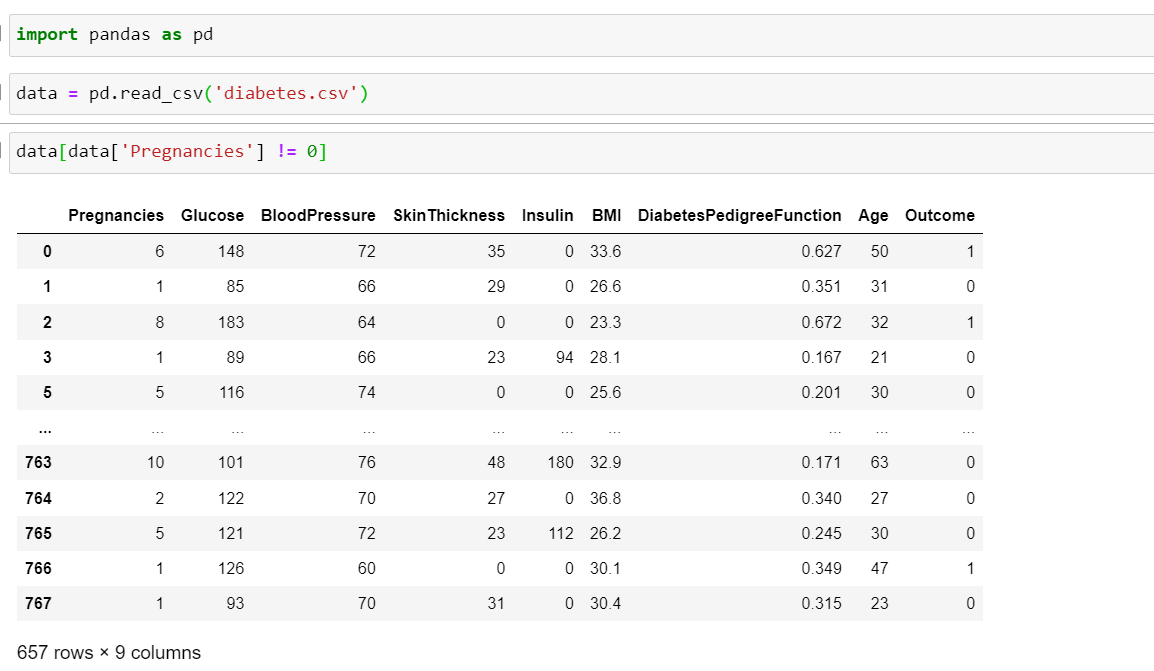
However, when I try to filter two or more columns I get different number of rows depending on whether I do like this:
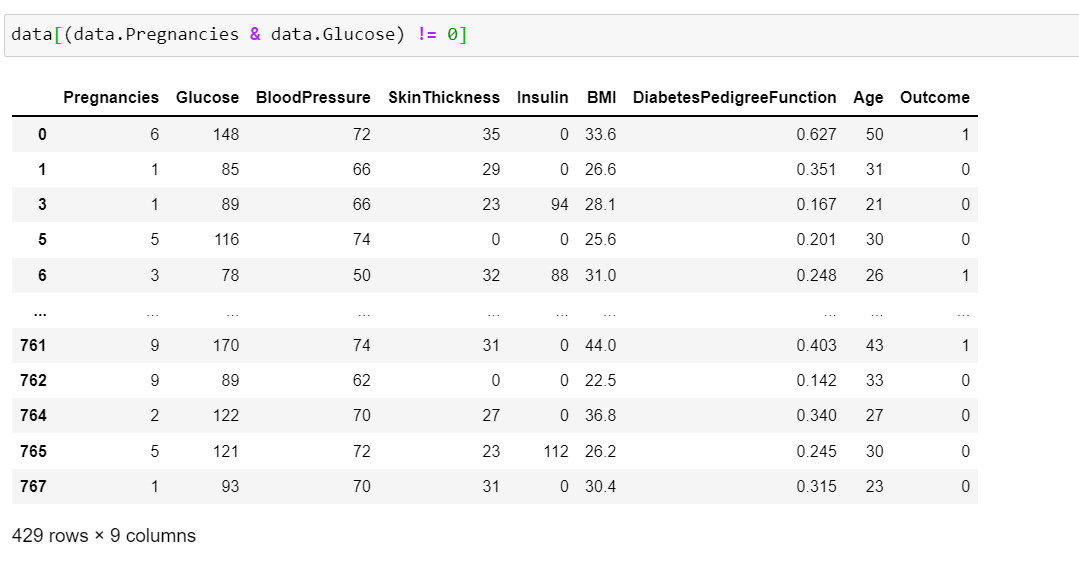
or this:
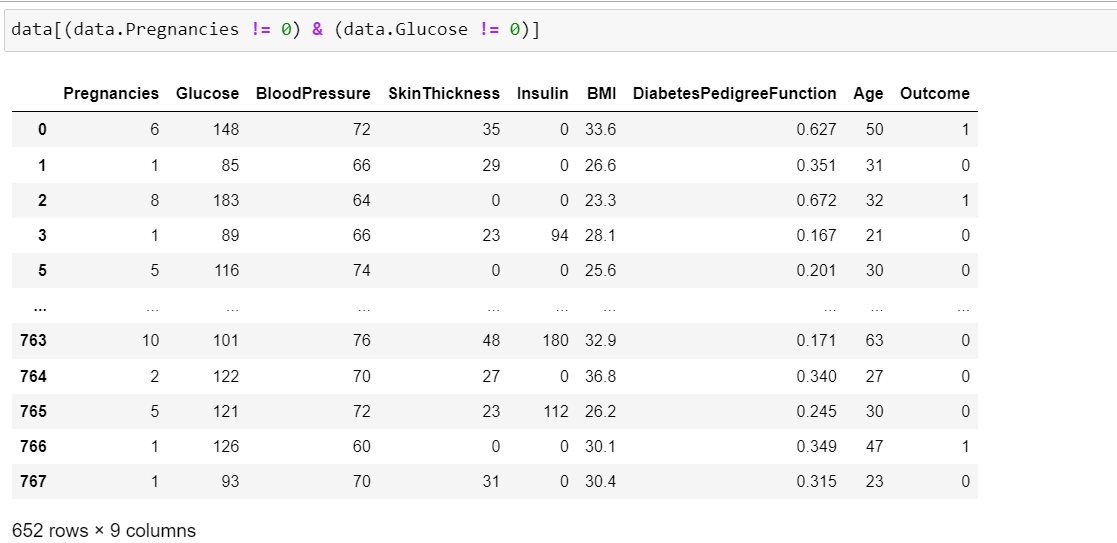
with me getting 429 rows and 652 rows respectively.
So I tried filtering with iloc:
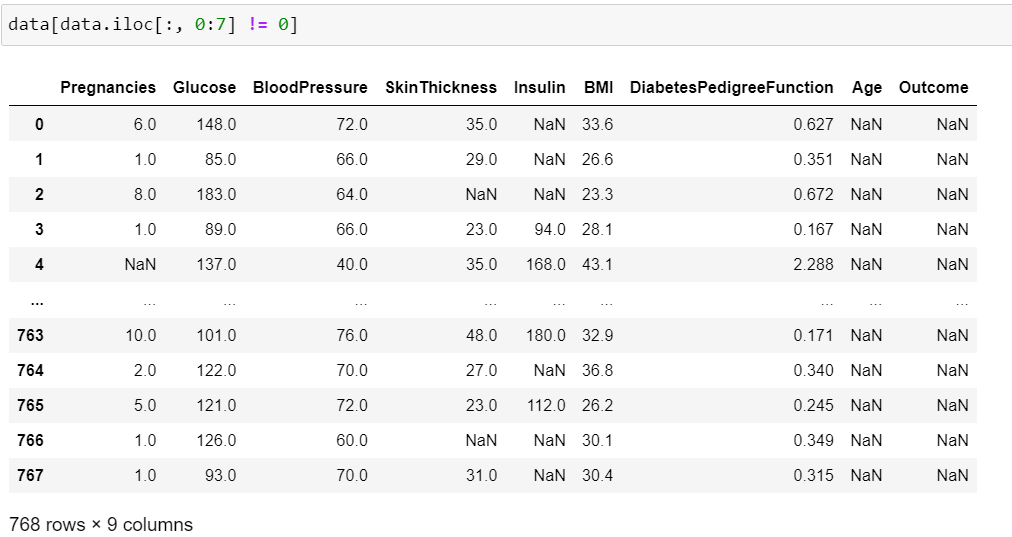
but that just fills the columns with NaN but doesn't remove the rows. Also it alters the Outcome column, which I want to keep intact. Seems like this iloc method only works when filtering one column at a time.
Is there some way how to filter the 8 columns at once instead of just doing one at a time?
CodePudding user response:
You can use apply to filter all columns at once, check in each if a value is 0 and return true if any.
result = df.drop(["Outcome"], axis=1).apply(lambda x: x == 0 , axis=0).any(1)
df[result]
CodePudding user response:
You could do something like this:
df[df.loc[:, 0:5] < 10].dropna(how='all', axis=1).dropna()
What that does, is it first creates a mask selecting all values of the first 5 columns that are less than 10. Then, it selects all the values from the dataframe selected by that mask.
Because the mask doesn't select all the columns, indexing the dataframe with that mask will return the columns that weren't accounted for by that mask (columns 6 onwards) as pure NaN values. .dropna(how='all', axis=1) will drop all columns that are all NaN.
Finally, .dropna() will remove all rows that contain any NaNs, leaving you with all rows where all values match the condition (are less than 10).