I have this data set that's in "long format" which I have listed below.
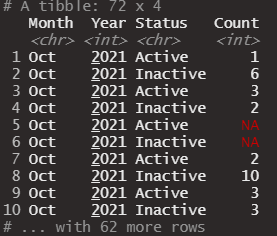
My goal is convert this data into a shorter format. I have this code but I keep getting NA's in the Sum column.
data %>%
group_by(Month, Year, Status) %>%
summarise(Sum = sum(Count))
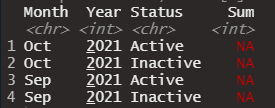
data
data <- structure(list(Month = c("Oct", "Oct", "Oct", "Oct", "Oct", "Oct",
"Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct",
"Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct",
"Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct", "Oct",
"Oct", "Oct", "Oct", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep",
"Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep",
"Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep",
"Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep", "Sep",
"Sep", "Sep", "Sep"), Year = c(2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L, 2021L,
2021L, 2021L, 2021L, 2021L), Status = c("Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive", "Active", "Inactive",
"Active", "Inactive", "Active", "Inactive"), Count = c(1L, 6L,
3L, 2L, NA, NA, 2L, 10L, 3L, 3L, 208L, 327L, 12L, 10L, 192L,
1L, NA, NA, 1L, 1L, 223L, 3L, 278L, 454L, 5L, 6L, 2L, 8L, 31L,
2L, 6L, 5L, 7L, 4L, 3L, 1L, 2L, 4L, 0L, 8L, 3L, 2L, 7L, 4L, 5L,
3L, 175L, 259L, 18L, 19L, NA, NA, 179L, 49L, 1L, 1L, 191L, 2L,
190L, 313L, 3L, 4L, 4L, 3L, NA, NA, 8L, 3L, 11L, 1L, NA, NA)), row.names = c(NA,
-72L), class = c("tbl_df", "tbl", "data.frame"))
CodePudding user response:
I think you just needed the na.rm = TRUE part in the Sum
out <- data %>%
dplyr::group_by(Month, Year, Status) %>%
dplyr::summarise(Sum = sum(Count, na.rm = TRUE))
out
# A tibble: 4 x 4
# Groups: Month, Year [2]
Month Year Status Sum
<chr> <int> <chr> <int>
1 Oct 2021 Active 977
2 Oct 2021 Inactive 843
3 Sep 2021 Active 797
4 Sep 2021 Inactive 675
CodePudding user response:
You pretty much have the code correct. You just need to account for the NAs with na.rm = TRUE.
library(dplyr)
data %>%
dplyr::group_by(Month, Year, Status) %>%
dplyr::summarise(Sum = sum(Count, na.rm = TRUE))
Output
# A tibble: 4 × 5
# Groups: Month, Year [2]
Month Year Status Sum
<chr> <int> <chr> <int>
1 Oct 2021 Active 977
2 Oct 2021 Inactive 843
3 Sep 2021 Active 797
4 Sep 2021 Inactive 675
Then, if you want to get the percentage for each Status by Month and Year, then you can mutate a new column.
data %>%
dplyr::group_by(Month, Year, Status) %>%
dplyr::summarise(Sum = sum(Count, na.rm = TRUE)) %>%
# Need to ungroup the Status column.
dplyr::ungroup(Status) %>%
dplyr::mutate(percent = (Sum / sum(Sum)) * 100)
Output
# A tibble: 4 × 5
# Groups: Month, Year [2]
Month Year Status Sum percent
<chr> <int> <chr> <int> <dbl>
1 Oct 2021 Active 977 53.7
2 Oct 2021 Inactive 843 46.3
3 Sep 2021 Active 797 54.1
4 Sep 2021 Inactive 675 45.9