I'm new to R, and I believe my problem may require more than just R knowledge. My data set is made up of weekly measurements taken at 10-minute intervals. The measurement begins at 4 a.m. and ends at 3.50 a.m. over the course of 24 hours (e.g. 7days x 144 measurements [24hours x 60minutes / 10 every10minutes]).
Variables definition:
day1_1=the first measurement of day 1
day1_2=the second measurement of day 1
....
day2_1 = the first measurement of day 2
day2_2 = the second measurement of day 2
......
id=identification number
a.)First, I would like to identify measurements that were taken at the same time over the course of a week per id.
For example how to identify if there are similar values for the first measurement during the week; eg. day1_1 measurement =day2_1 measurement = ...=day7_1 measurement?
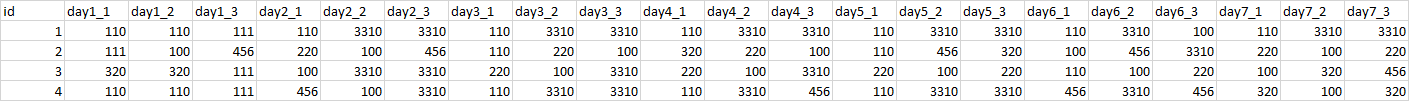
Sample data in long:
structure(list(id = c(1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1,
2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2,
3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3,
4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4,
1, 2, 3, 4, 1, 2, 3, 4), variable = structure(c(1L, 1L, 1L, 1L,
2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 5L, 5L, 5L, 5L,
6L, 6L, 6L, 6L, 7L, 7L, 7L, 7L, 8L, 8L, 8L, 8L, 9L, 9L, 9L, 9L,
10L, 10L, 10L, 10L, 11L, 11L, 11L, 11L, 12L, 12L, 12L, 12L, 13L,
13L, 13L, 13L, 14L, 14L, 14L, 14L, 15L, 15L, 15L, 15L, 16L, 16L,
16L, 16L, 17L, 17L, 17L, 17L, 18L, 18L, 18L, 18L, 19L, 19L, 19L,
19L, 20L, 20L, 20L, 20L, 21L, 21L, 21L, 21L), .Label = c("day1_1",
"day1_2", "day1_3", "day2_1", "day2_2", "day2_3", "day3_1", "day3_2",
"day3_3", "day4_1", "day4_2", "day4_3", "day5_1", "day5_2", "day5_3",
"day6_1", "day6_2", "day6_3", "day7_1", "day7_2", "day7_3"), class = "factor"),
value = c(110, 111, 320, 110, 110, 100, 320, 110, 111, 456,
111, 111, 110, 220, 100, 456, 3310, 100, 3310, 100, 3310,
456, 3310, 3310, 110, 110, 220, 110, 3310, 220, 100, 3310,
3310, 100, 3310, 3310, 110, 320, 220, 110, 3310, 220, 100,
3310, 3310, 100, 3310, 456, 110, 110, 220, 110, 3310, 456,
100, 3310, 3310, 320, 220, 3310, 110, 100, 110, 456, 3310,
456, 100, 3310, 100, 3310, 220, 456, 110, 220, 100, 320,
3310, 100, 320, 100, 3310, 220, 456, 320)), row.names = c(NA,
-84L), class = "data.frame")
Sample data:
structure(list(id = c(1, 2, 3, 4), day1_1 = c(110, 111, 320,
110), day1_2 = c(110, 100, 320, 110), day1_3 = c(111, 456, 111,
111), day2_1 = c(110, 220, 100, 456), day2_2 = c(3310, 100, 3310,
100), day2_3 = c(3310, 456, 3310, 3310), day3_1 = c(110, 110,
220, 110), day3_2 = c(3310, 220, 100, 3310), day3_3 = c(3310,
100, 3310, 3310), day4_1 = c(110, 320, 220, 110), day4_2 = c(3310,
220, 100, 3310), day4_3 = c(3310, 100, 3310, 456), day5_1 = c(110,
110, 220, 110), day5_2 = c(3310, 456, 100, 3310), day5_3 = c(3310,
320, 220, 3310), day6_1 = c(110, 100, 110, 456), day6_2 = c(3310,
456, 100, 3310), day6_3 = c(100, 3310, 220, 456), day7_1 = c(110,
220, 100, 320), day7_2 = c(3310, 100, 320, 100), day7_3 = c(3310,
220, 456, 320)), class = c("spec_tbl_df", "tbl_df", "tbl", "data.frame"
), row.names = c(NA, -4L), spec = structure(list(cols = list(
id = structure(list(), class = c("collector_double", "collector"
)), day1_1 = structure(list(), class = c("collector_double",
"collector")), day1_2 = structure(list(), class = c("collector_double",
"collector")), day1_3 = structure(list(), class = c("collector_double",
"collector")), day2_1 = structure(list(), class = c("collector_double",
"collector")), day2_2 = structure(list(), class = c("collector_double",
"collector")), day2_3 = structure(list(), class = c("collector_double",
"collector")), day3_1 = structure(list(), class = c("collector_double",
"collector")), day3_2 = structure(list(), class = c("collector_double",
"collector")), day3_3 = structure(list(), class = c("collector_double",
"collector")), day4_1 = structure(list(), class = c("collector_double",
"collector")), day4_2 = structure(list(), class = c("collector_double",
"collector")), day4_3 = structure(list(), class = c("collector_double",
"collector")), day5_1 = structure(list(), class = c("collector_double",
"collector")), day5_2 = structure(list(), class = c("collector_double",
"collector")), day5_3 = structure(list(), class = c("collector_double",
"collector")), day6_1 = structure(list(), class = c("collector_double",
"collector")), day6_2 = structure(list(), class = c("collector_double",
"collector")), day6_3 = structure(list(), class = c("collector_double",
"collector")), day7_1 = structure(list(), class = c("collector_double",
"collector")), day7_2 = structure(list(), class = c("collector_double",
"collector")), day7_3 = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), skip = 1L), class = "col_spec"))
CodePudding user response:
Maybe this might help you.
library(tidyverse)
data <- structure(list(id = c(1, 2, 3, 4), day1_1 = c(
110, 111, 320,
110
), day1_2 = c(110, 100, 320, 110), day1_3 = c(
111, 456, 111,
111
), day2_1 = c(110, 220, 100, 456), day2_2 = c(
3310, 100, 3310,
100
), day2_3 = c(3310, 456, 3310, 3310), day3_1 = c(
110, 110,
220, 110
), day3_2 = c(3310, 220, 100, 3310), day3_3 = c(
3310,
100, 3310, 3310
), day4_1 = c(110, 320, 220, 110), day4_2 = c(
3310,
220, 100, 3310
), day4_3 = c(3310, 100, 3310, 456), day5_1 = c(
110,
110, 220, 110
), day5_2 = c(3310, 456, 100, 3310), day5_3 = c(
3310,
320, 220, 3310
), day6_1 = c(110, 100, 110, 456), day6_2 = c(
3310,
456, 100, 3310
), day6_3 = c(100, 3310, 220, 456), day7_1 = c(
110,
220, 100, 320
), day7_2 = c(3310, 100, 320, 100), day7_3 = c(
3310,
220, 456, 320
)), class = c("spec_tbl_df", "tbl_df", "tbl", "data.frame"), row.names = c(NA, -4L), spec = structure(list(cols = list(
id = structure(list(), class = c("collector_double", "collector")), day1_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day1_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day1_3 = structure(list(), class = c(
"collector_double",
"collector"
)), day2_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day2_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day2_3 = structure(list(), class = c(
"collector_double",
"collector"
)), day3_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day3_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day3_3 = structure(list(), class = c(
"collector_double",
"collector"
)), day4_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day4_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day4_3 = structure(list(), class = c(
"collector_double",
"collector"
)), day5_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day5_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day5_3 = structure(list(), class = c(
"collector_double",
"collector"
)), day6_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day6_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day6_3 = structure(list(), class = c(
"collector_double",
"collector"
)), day7_1 = structure(list(), class = c(
"collector_double",
"collector"
)), day7_2 = structure(list(), class = c(
"collector_double",
"collector"
)), day7_3 = structure(list(), class = c(
"collector_double",
"collector"
))
), default = structure(list(), class = c(
"collector_guess",
"collector"
)), skip = 1L), class = "col_spec"))
data_2 <-
data %>%
pivot_longer(-id) %>%
separate(name, into = c("day", "timepoint"), sep = "_") %>%
arrange(timepoint)
data_2
#> # A tibble: 84 x 4
#> id day timepoint value
#> <dbl> <chr> <chr> <dbl>
#> 1 1 day1 1 110
#> 2 1 day2 1 110
#> 3 1 day3 1 110
#> 4 1 day4 1 110
#> 5 1 day5 1 110
#> 6 1 day6 1 110
#> 7 1 day7 1 110
#> 8 2 day1 1 111
#> 9 2 day2 1 220
#> 10 2 day3 1 110
#> # … with 74 more rows
# select specific days
data_2 %>%
filter(day == "day2")
#> # A tibble: 12 x 4
#> id day timepoint value
#> <dbl> <chr> <chr> <dbl>
#> 1 1 day2 1 110
#> 2 2 day2 1 220
#> 3 3 day2 1 100
#> 4 4 day2 1 456
#> 5 1 day2 2 3310
#> 6 2 day2 2 100
#> 7 3 day2 2 3310
#> 8 4 day2 2 100
#> 9 1 day2 3 3310
#> 10 2 day2 3 456
#> 11 3 day2 3 3310
#> 12 4 day2 3 3310
# measurements for an id on a day with the same value
data_2 %>%
group_by(id, day, value) %>%
count() %>%
filter(n > 1)
#> # A tibble: 15 x 4
#> # Groups: id, day, value [15]
#> id day value n
#> <dbl> <chr> <dbl> <int>
#> 1 1 day1 110 2
#> 2 1 day2 3310 2
#> 3 1 day3 3310 2
#> 4 1 day4 3310 2
#> 5 1 day5 3310 2
#> 6 1 day7 3310 2
#> 7 2 day7 220 2
#> 8 3 day1 320 2
#> 9 3 day2 3310 2
#> 10 3 day5 220 2
#> 11 4 day1 110 2
#> 12 4 day3 3310 2
#> 13 4 day5 3310 2
#> 14 4 day6 456 2
#> 15 4 day7 320 2
# Overview plot
qplot(x = timepoint, y = value, color = day, data = data_2, geom = "point", size = 5)
facet_wrap(~id)
Created on 2021-11-23 by the reprex package (v2.0.1)
CodePudding user response:
I prefer data.table to manipulate my data, but you can do with dplyr as well of course. Either way, starting with R and data, it is advisable to study one of them at least. I suggest to prepare your data like this, so you have a seperate column for your day and for timeslot.
dt <- copy(df)
library(data.table)
setDT(dt)
dt <- melt(dt, id = c("id"))
cols <- c("day", "timeslot")
dt[, (cols) := tstrsplit(str_remove_all(variable, "[[:alpha:]]"), "_", fixed = T)]
dt[, (cols) := lapply(.SD, as.numeric), .SDcols = cols]
head(dt, 15)
# id variable value day timeslot
# 1: 1 day1_1 110 1 1
# 2: 2 day1_1 111 1 1
# 3: 3 day1_1 320 1 1
# 4: 4 day1_1 110 1 1
# 5: 1 day1_2 110 1 2
# 6: 2 day1_2 100 1 2
# 7: 3 day1_2 320 1 2
# 8: 4 day1_2 110 1 2
# 9: 1 day1_3 111 1 3
# 10: 2 day1_3 456 1 3
# 11: 3 day1_3 111 1 3
# 12: 4 day1_3 111 1 3
# 13: 1 day2_1 110 2 1
# 14: 2 day2_1 220 2 1
# 15: 3 day2_1 100 2 1
str(dt)
# Classes ‘data.table’ and 'data.frame': 84 obs. of 5 variables:
# $ id : num 1 2 3 4 1 2 3 4 1 2 ...
# $ variable: Factor w/ 21 levels "day1_1","day1_2",..: 1 1 1 1 2 2 2 2 3 3 ...
# $ value : num 110 111 320 110 110 100 320 110 111 456 ...
# $ day : num 1 1 1 1 1 1 1 1 1 1 ...
# $ timeslot: num 1 1 1 1 2 2 2 2 3 3 ...
From here you can play around with this data and answer your questions.