I am trying to scrape 100.0% from style attribute:
<div class="w-full mt-1 bg-white rounded-lg shadow">
<div class="py-1 bg-purple-900 rounded-lg" style="width: 100.0%"></div>
</div>
The page source response does not go this deep into the page, I have tried:
def ScrapePercents():
URL = "https://citystrides.com/cities/26013/search_striders?page=1"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
results = soup.find("div", class_="flex flex-wrap space-y-4")
percents = results.find_all("div", class_="py-1 bg-purple-900 rounded-lg")
pl = []
for percent in percents:
cleantext = percent['style'].lstrip('width: ')
percent_neat = (cleantext.strip('%'))
percent_float = float(percent_neat)
pl.append(percent_float)
print("pl as it appends ", pl)
return pl
And
def Selenium():
print("shell for selenium")
pl = "shell for selenium percents"
driver = webdriver.Chrome("chromedriver.exe")
driver.get("https://citystrides.com/cities/26013/search_striders")
content = driver.page_source
soup = BeautifulSoup(content)
results = soup.find("div", class_="flex flex-wrap space-y-4")
return soup
The second code is set just to see whether the content includes the nested div. I'm struggling to work out how to get the nested div.
CodePudding user response:
the element/div you are looking for with class w-full and py-1 are actually not there in the source of the website, I just tried to inspect and could not find them,can you see them when you open that website on your browser?
CodePudding user response:
Using Selenium to extract the DIV content you need to induce WebDriverWait for the visibility_of_element_located() and you can use either of the following Locator Strategies:
Using
CSS_SELECTOR:driver.get("https://citystrides.com/cities/26013/search_striders") print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, ".flex.flex-wrap.space-y-4"))).get_attribute("innerHTML"))Using
XPATH:driver.get("https://citystrides.com/cities/26013/search_striders") print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[@class='flex flex-wrap space-y-4']"))).get_attribute("innerHTML"))Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
Console Output:
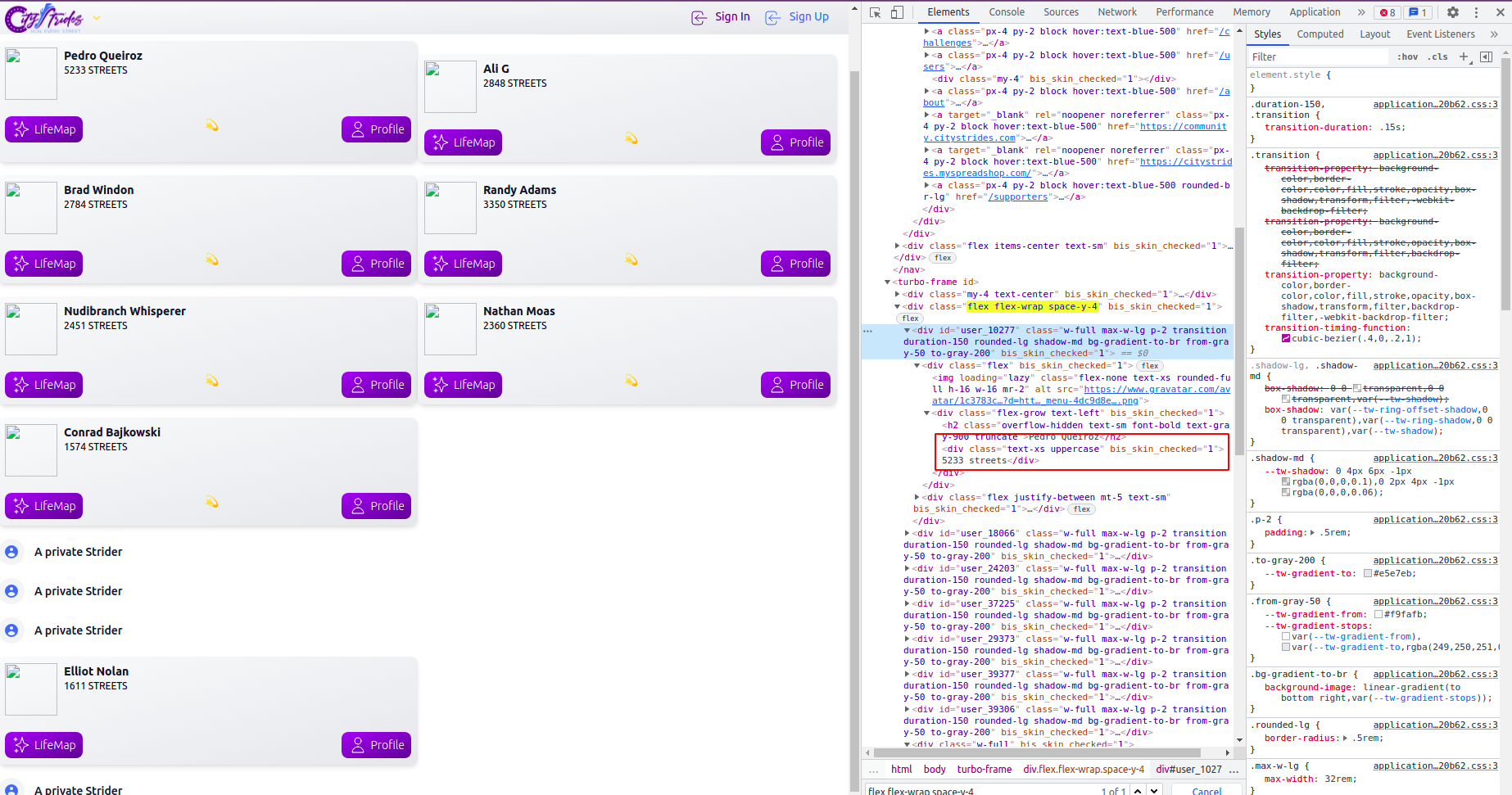
<div id="user_10277" class="w-full max-w-lg p-2 transition duration-150 rounded-lg shadow-md bg-gradient-to-br from-gray-50 to-gray-200">
<div class="flex-grow text-left">
<h2 class="overflow-hidden text-sm font-bold text-gray-900 truncate">Pedro Queiroz</h2>
<div class="text-xs uppercase">5233 streets</div>
</div>
</div>
<div class="flex justify-between mt-5 text-sm">
<div>
<a data-turbo-frame="_top" class="purple-button flex items-center" href="/users/10277/map">
<svg class="float-left w-6 h-6 mr-1" fill="none" stroke-linecap="round" stroke-linejoin="round" stroke-width="1" viewBox="0 0 24 24" stroke="currentColor"><path d="M5 3v4M3 5h4M6 17v4m-2-2h4m5-16l2.286 6.857L21 12l-5.714 2.143L13 21l-2.286-6.857L5 12l5.714-2.143L13 3z"></path></svg>
LifeMap
</a> </div>
<div title="Pedro Queiroz is a Supporter">