I'm unable to find the ratings (number next to the stars) at 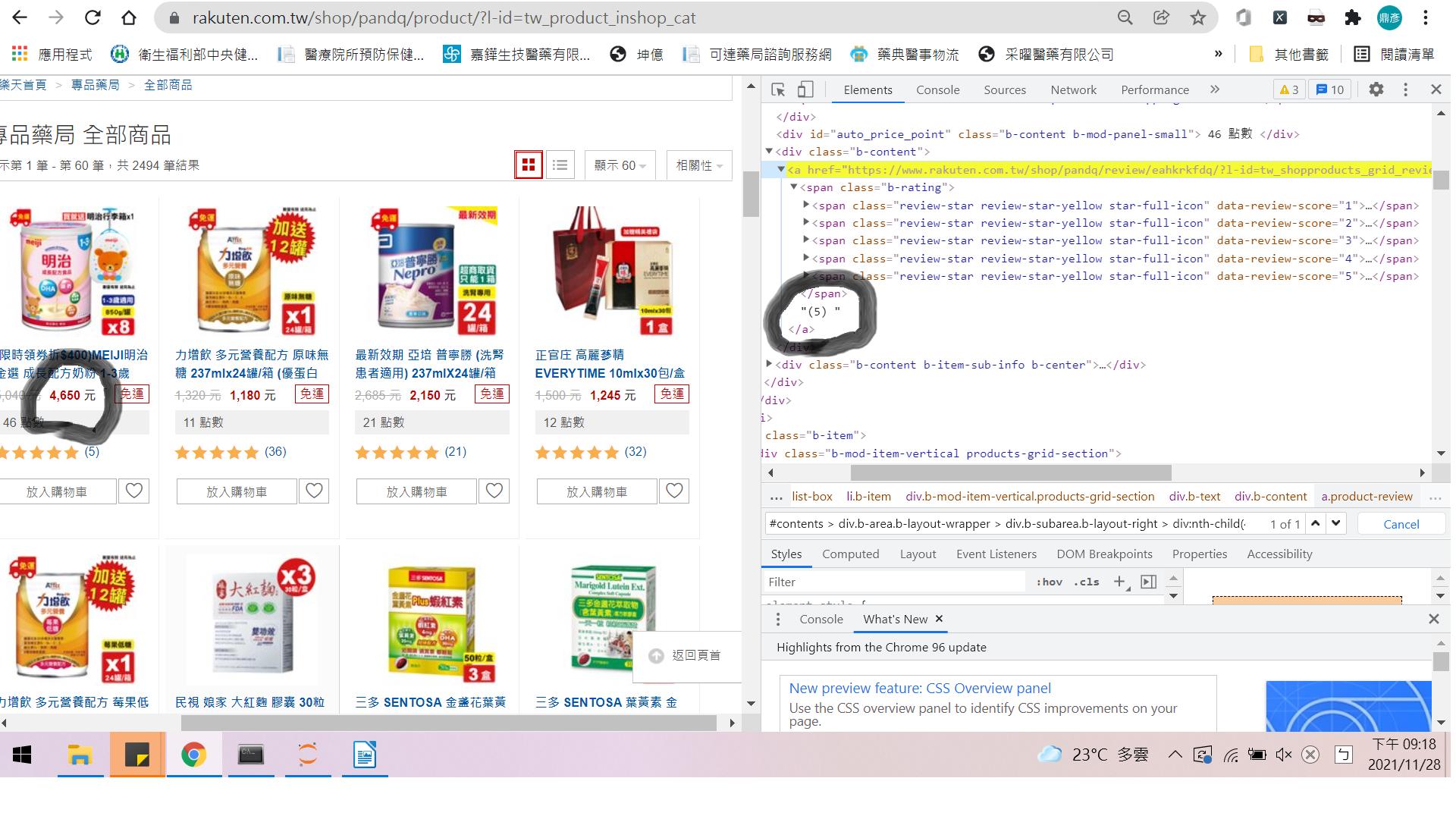
import time
import requests
!pip install beautifulsoup4
import bs4
!pip install lxml
from bs4 import BeautifulSoup
import pandas as pd
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'}
products =[]
for i in range(1,2): # Iterate from page 1 to the last page
url = "https://www.rakuten.com.tw/shop/pandq/product/?l-id=tw_shop_inshop_cat&p={}".format(i)
r = requests.get(url, headers = headers)
soup = bs4.BeautifulSoup(r.text,"lxml")
Soup = soup.find_all("div",class_='b-mod-item-vertical products-grid-section')
for product in Soup:
productcount = product.find_all("div",class_='b-content')
print(productcount)
CodePudding user response:
What happens?
Selection of element is not that proper, so you wont get the expected result.
How to fix?
As your Screen shot shows different things price / rating I will focus on rating.
First select all the items:
soup.select('.b-item')
Then iterate the result set and select the <a> that holds the rating:
item.select_one('.product-review')
Get rid of all the special characters:
item.select_one('.product-review').get_text(strip=True).strip('(|)')
Example
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
r = requests.get('https://www.rakuten.com.tw/shop/pandq/product/?l-id=tw_shop_inshop_cat&p=1',headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
for item in soup.select('.b-item'):
rating = item.select_one('.product-review').get_text(strip=True).strip('(|)') if item.select_one('.product-review') else None
print(rating)
Output
5
36
21
32
8
...