Assuming I have this dataframe saved in my directory:
import numpy as np
import pandas as pd
col1 = pd.Series(np.linspace(1, 10, 20))
col2 = pd.Series(np.linspace(11, 20, 20))
data = np.array([col1, col2]).T
df = pd.DataFrame(data, columns = ["col1", "col2"])
df.to_csv("test.csv", index = False)
What I would like to do is to read this file and the name of the file as a column on top of the other columns to get something like this:
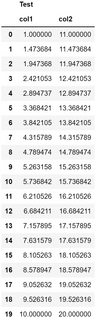
How can I do this?
CodePudding user response:
file = 'test.csv'
df = pd.read_csv(file)
name = file.split('.')[0].capitalize()
df.columns= pd.MultiIndex.from_product([[name],df.columns])
print (df.head())
Test
col1 col2
0 1.000000 11.000000
1 1.473684 11.473684
2 1.947368 11.947368
3 2.421053 12.421053
4 2.894737 12.894737
CodePudding user response:
Use pathlib to extract the file name using .stem and pd.concat to create a multi level column:
import pathlib
filename = pathlib.Path('path/to/test.csv')
df = pd.concat({filename.stem.capitalize(): pd.read_csv(filename)}, axis=1)
print(df)
# Output:
Test
col1 col2
0 1.000000 11.000000
1 1.473684 11.473684
2 1.947368 11.947368
3 2.421053 12.421053
4 2.894737 12.894737
5 3.368421 13.368421
6 3.842105 13.842105
7 4.315789 14.315789
8 4.789474 14.789474
9 5.263158 15.263158
10 5.736842 15.736842
11 6.210526 16.210526
12 6.684211 16.684211
13 7.157895 17.157895
14 7.631579 17.631579
15 8.105263 18.105263
16 8.578947 18.578947
17 9.052632 19.052632
18 9.526316 19.526316
19 10.000000 20.000000