I asked a similar question a few days ago on here and it was great help! A new challenge I wanted build is to further develop the regex pattern to look for specific formats in this iteration, and I thought I have solved it using regex 101 to build/test a regex code but when applied in Python received 'pattern contain no group'. Below is a test df, and a image of what the results should be like/code that was provided via StackOverflow that worked with digits only.
df = pd.DataFrame([["{1} | | Had a Greeter welcome clients {1.0} | | Take measures to ensure a safe and organized distribution {1.000} | | Protected confidentiality of clients (on social media, pictures, in conversation, own congregation members receiving assistance, etc.)",
"{1.00} | | Chairs for clients to sit in while waiting {1.0000} | | Take measures to ensure a safe and organized distribution"],
["{1 } | Financial literacy/budgeting {1 } | | Monetary/Bill Support {1} | | Mental Health Services/Counseling",
"{1}| | Clothing Assistance {1 } | | Healthcare {1} | | Mental Health Services/Counseling {1} | | Spiritual Support {1} | | Job Skills Training"]
] , columns = ['CF1', 'CF2'])
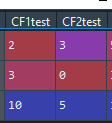
Here is the iteration code that worked digits only. I changed the pattern search with my new regex pattern and it did not work.
Original code: (df.stack().str.extractall('(\d )')[0] .groupby(level=[0,1]).sum().unstack())
New Code (Failed to recognize pattern): (df.stack().str.extractall(r'(?<=\{)[\d \.\ ] (?=\})')[0].astype(int) .groupby(level=[0,1]).sum().unstack())
**In the test df you will see I want to only capture the numbers between "{}" and there's a mixture of decimals and spaces following the number I want to capture and sum. The new pattern did not work in application so any help would be great! **
CodePudding user response:
Your (?<=\{)[\d \.\ ] (?=\}) regex contains no capturing groups while Series.str.extractall requires at least one capturing group to output a value.
You need to use
(df.stack().str.extractall(r'\{\s*(\d (?:\.\d )?)\s*}')[0].astype(float) .groupby(level=[0,1]).sum().unstack())
Output:
CF1 CF2
0 3.0 2.0
1 3.0 5.0
The \{\s*(\d (?:\.\d )?)\s*} regex matches
\{- a{char\s*- zero or more whitespaces(\d (?:\.\d )?)- Group 1 (note this group captured value will be the output of theextractallmethod, it requires at least one capturing group): one or more digits, and then an optional occurrence of a.and one or more digits\s*- zero or more whitespaces}- a}char.
See the regex demo.
CodePudding user response:
You can use '\{([\d.] )\}':
(df.stack().str.extractall(r'\{([\d.] )\}')[0]
.astype(float).groupby(level=[0,1]).sum().unstack())
output:
CF1 CF2
0 3.0 2.0
1 1.0 4.0
as int only:
(df.stack().str.extractall(r'\{(\d )(?:\.\d )?\}')[0]
.astype(int).groupby(level=[0,1]).sum().unstack())
output:
CF1 CF2
0 3 2
1 1 4