I'm trying to extract data from xls-files, which have always the same structure (see below). After extracting the ranges of interest with:
all_data <- (file.path(wdir, 'data_input.xlsx'))
excel_sheets(path = all_results)
tab_names <- excel_sheets(path = all_results)
extracted_data <- lapply(tab_names, function(x) read_excel(all_data,
sheet = x, col_names=FALSE, range = "B2:B4"))
I would like to bring everything into a wide format. Yet, when I use:
extracted_data_wide <- extracted_data %>% bind_rows(extracted_data, .id=NULL)
it seems to repeat all inputs once, which is not plausible for me. Is there anyone who can help me understand where the problem is or who could probably offer a different solution for my question? I had also thought on pivot_wider but it doesn't work with the output extracted_data the way I thought.
Example data:
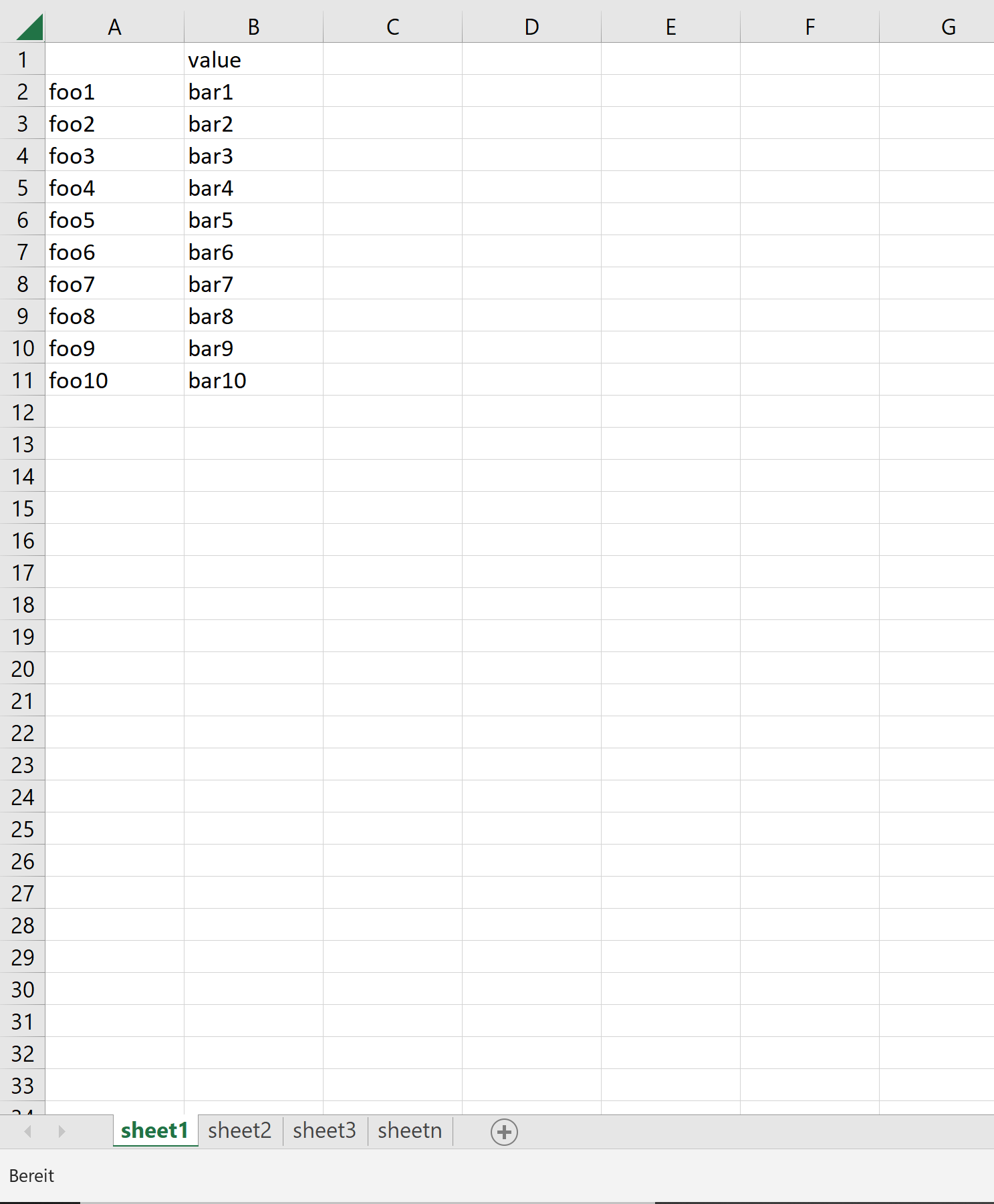
CodePudding user response:
Still not really sure about your desired result, but I give it a try
- As you want two columns
foo1andfoo2I would guess that you want to extract only the first two rows of your data. - Instead of just getting the values in column B of your excel sheets extract the names in column A too, using
range="A2:B3". - Afterwards use bind_rows. One issue with your code was that you passed the list of dataframe two times to
bind_rows. - When using
bind_rowsadd an.idfor the sheets - Besides renaming you could then use
pivot_widerto convert your data to wide format with rows corresponding to sheets and columns corresponding to the rows of your excel sheets
# Make example data
all_results <- tempfile(fileext = ".xlsx")
d1 <- data.frame(
name = paste0("foo", 1:10),
value = paste0("bar", 1:10)
)
d2 <- data.frame(
name = paste0("foo", 1:10),
value = paste0("bar", 11:20)
)
writexl::write_xlsx(list(d1, d2), path = all_results)
library(readxl)
library(dplyr)
library(tidyr)
tab_names <- excel_sheets(path = all_results)
extracted_data <- lapply(tab_names, function(x) read_excel(all_results, sheet = x, col_names=FALSE, range = "A2:B3"))
#> New names:
#> * `` -> ...1
#> * `` -> ...2
#> New names:
#> * `` -> ...1
#> * `` -> ...2
extracted_data_wide <- extracted_data %>% bind_rows(.id = "sheet")
extracted_data_wide %>%
rename(foo = 2, value = 3) %>%
pivot_wider(names_from = foo, values_from = value)
#> # A tibble: 2 × 3
#> sheet foo1 foo2
#> <chr> <chr> <chr>
#> 1 1 bar1 bar2
#> 2 2 bar11 bar12