Here is how my data is configured in my order table:
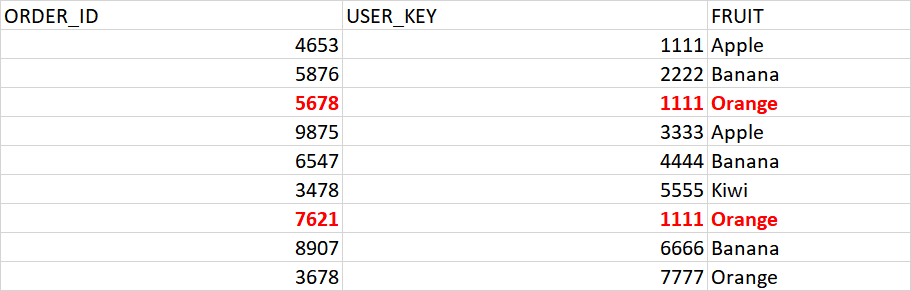
I have 3 fields: ORDER_ID, that is the unique field per ORDER (only appears once in the whole table), USER_KEY, that is the unique field per BUYER (buyers can place multiple orders and can appear multiple times in the order table), and FRUIT, that identifies the item that has been bought per order.
I need to identify the buyers (USER_KEY), that have purchases multiples of the same products.
I have the following query to identify these buyers:
select
t.user_key from temp t
inner join (
SELECT user_key,
Count(order_id) as [Minimum of 2 Count] from temp group by user_key, fruit
) it on t.user_key = it.user_key and it.[Minimum of 2 Count] > 1
group by t.user_key;
This query however does not work in SNOWFLAKE. Does anyone know how I can tweak the syntax of this query to work in Snowflake?
Thank you!
CodePudding user response:
The identifiers are quoted with " - [] are probably Sybase or T-SQL syntax:
select t.user_key from temp t
inner join (
SELECT user_key,
Count(order_id) as "Minimum of 2 Count" from temp group by user_key, fruit
) it on t.user_key = it.user_key and it."Minimum of 2 Count" > 1
group by t.user_key;
Anyway the query coud be rewritten:
SELECT DISTINCT user_key
FROM temp t
QUALIFY COUNT(order_id) OVER(PARTITION BY user_key, fruit) > 1;
or:
SELECT DISTINCT user_key
FROM temp
GROUP BY user_key, fruit
HAVING COUNT(ORDER_ID) > 1;
CodePudding user response:
First get all your results where user and fruit are the same and count those results.
You then filter the result in an outer query:
SELECT
user_key
FROM
(
SELECT
t1.user_key as user_key,
count(t1.user_key) as num_user
FROM
temp t1
temp t2
WHERE
t1.user_key = t2.user_key
AND t1.fruit = t2.fruit
GROUP BY
t1.user_key
)
WHERE
num_user > 2
CodePudding user response:
We can use either windows function or group based on what columns you are looking:
select user_key, fruit, count(1) from Test1
group by user_key, fruit
having count(1)>1;