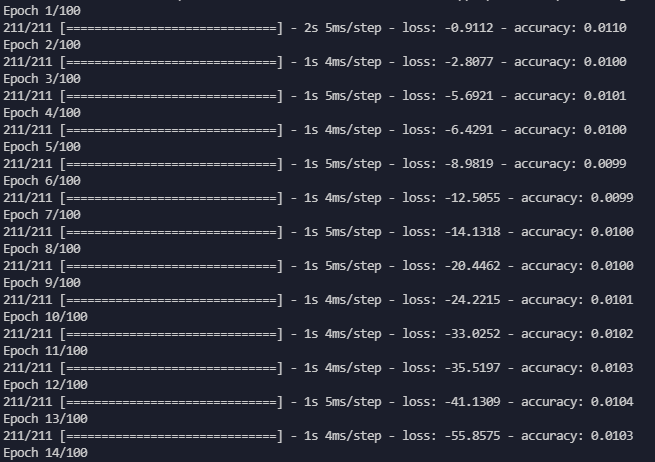
I'm trying to create a neural network for a classification problem about audios of me talking and audios of other people talking, so it classify it. But when I train it, it give me this weird result of accuracy and loss.
Here is my code.
'''
This is only to read the data and pass it into an array
1. Get the Audio data, my voice so we can visualize it into an array.
2. Build an ANN with the data already into an array. classification problem
3. Real time predictor using pyaudio and trained model
'''
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.layers.core import Dropout
from sklearn.preprocessing import StandardScaler
import tensorflow as tf
import numpy as np
from scipy.io import wavfile
from pathlib import Path
import os
# cut audio to make the same sizes, shape and length
def trim_wav( originalWavPath, newWavPath , start, new ):
'''
:param originalWavPath: the path to the source wav file
:param newWavPath: output wav file * can be same path as original
:param start: time in seconds
:param end: time in seconds
:return:
'''
sampleRate, waveData = wavfile.read( originalWavPath )
startSample = int( start * sampleRate )
endSample = int( new * sampleRate )
wavfile.write( newWavPath, sampleRate, waveData[startSample:endSample])
### DATASET
pathlist = Path(os.path.abspath('Voiceclassification/Data/me/')).rglob('*.wav')
# My voice data
for path in pathlist:
wp = str(path)
# Trim function here for each file
trim_wav(wp, wp.replace(".wav", ".wav"), 0,5)
filename = str(path)
# convert audio to numpy array and then 2D to 1D np Array
samplerate, data = wavfile.read(filename)
#print(f"sample rate: {samplerate}")
#print(f"data: {data}")
pathlist2 = Path(os.path.abspath('Voiceclassification/Data/other/')).rglob('*.wav')
# other voice data
for path2 in pathlist2:
wp2 = str(path2)
trim_wav(wp2, wp2.replace(".wav", ".wav"), 0,5)
filename2 = str(path2)
samplerate2, data2 = wavfile.read(filename2)
#print(data2)
### ADAPTING THE DATA FOR THE MODEL
X = data.reshape(-1, 1) # My voice
y = data2.reshape(-1, 1) # Other data
#print(X_.shape)
#print(y_.shape)
### Trainig the model
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
# Performing future scaling
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
### Creating the ANN
ann = tf.keras.models.Sequential()
# First hidden layer of the ann
ann.add(tf.keras.layers.Dense(units=6, activation="relu"))
ann.add(Dropout(0.05))
# Second one
ann.add(tf.keras.layers.Dense(units=6, activation="relu"))
ann.add(Dropout(0.05))
# Output layer
ann.add(tf.keras.layers.Dense(units=1, activation="sigmoid"))
# Compile our neural network
ann.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=['accuracy'])
# Fit ANN
ann.fit(x_train, y_train, batch_size=1024, epochs=100) ############ batch 32
ann.save('Models/voiceclassification.model')
does anyone know if there is anything wrong with my code that makes the acc very low?
CodePudding user response:
@MarkLavin, your answer was correct, I'm the same person that ask it, this is my other account the real one, I try what @MarkLavin told me to do and it work, I modify my code with this.
### DATASET
data = []
labels = []
audio_files = [f for f in glob.glob(os.path.abspath(r"Voiceclassification\Data") "/**/*", recursive=True) if not os.path.isdir(f)]
random.shuffle(audio_files)
# My voice data
for path in audio_files:
wp = str(path)
# Trim function here for each file
trim_wav(wp, wp.replace(".wav", ".wav"), 0,5)
filename = str(path)
# convert audio to numpy array and then 2D to 1D np Array
samplerate, data_array = wavfile.read(filename)
#print(f"data: {data}")
data_array.reshape(-1, 1)
data.append(data_array)
label = path.split(os.path.sep)[-2]
if label == "me":
label = 1
else:
label = 0
labels.append([label])
### ADAPTING THE DATA FOR THE MODEL
X = data # all voices data
y = np.array(labels) # data label 1 es me, 0 is other
Labels for y and all data with random for X, this are the results are 100% and 90% accuracy, thank you so much @MarkLavin :)