I have a large df ( 100k rows, see snapshot of data below) that I'm trying to summarize (min, mean, median, max, etc.) a variable (salinity) in a table by group (species) using tapply, but if I use the whole dataset (which contains a few NA's, but not in every group) instead of a random subset, tapply adds in an extra column in the table it creates called "NA.s" and it has a value for every group. I'm not sure what this column is or how it's created. Using a subset of randomly chosen rows from the df instead doesn't recreate this issue, so I'm not sure how to reproduce my data here...
I load my data:
then I run this code:
sum_stats <- tapply(df$salinity, df$species, summary)
Which seems to create a list of doubles (no NULLs) that look like this:
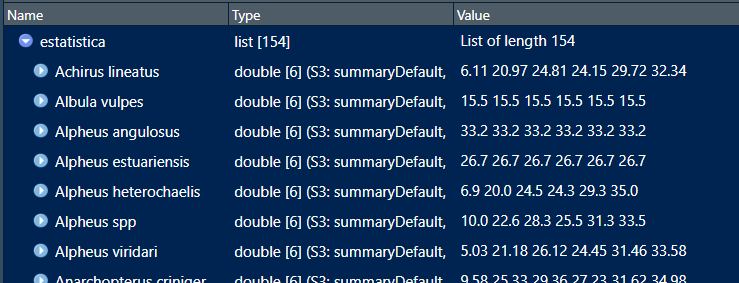
Clicking one of them yeilds this, all good:
> sum_stats[["Albula vulpes"]]
Min. 1st Qu. Median Mean 3rd Qu. Max.
15.49 15.49 15.49 15.49 15.49 15.49
Then creating a dataframe creates the issue somehow?
sum_data_table<-data.frame(do.call("rbind", sum_stats))
# Not sure what this is either
Warning message:
In rbind(`Achirus lineatus` = c(Min. = 6.11, `1st Qu.` = 20.97, :
number of columns of result is not a multiple of vector length (arg 1)
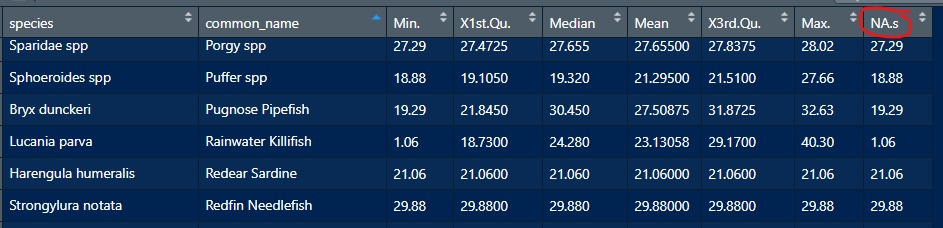
New unknown column circled in red:
CodePudding user response:
This will happen because some of the species will not have NAs while others will. summary will not have the NA column if there are none missing and rbind doesn’t know how to handle a differing number of columns. You’re seeing the first element repeated (the min) when there are none missing. For species that have some missing, you'll see the count of NA
set.seed(1)
x <- expand.grid(letters, letters, letters)
x <- paste0(x$Var1, x$Var2, x$Var3)[1:150]
df <- data.frame(
species = rep(x, 100),
salinity = rnorm(15000)
)
df$salinity[df$salinity < -2.2] <- NA
sum_stats <- tapply(df$salinity, df$species, summary)
sum_data_table<-data.frame(do.call("rbind", sum_stats))
#> Warning in rbind(aaa = structure(c(Min. = -1.7072100148514, `1st Qu.` =
#> -0.755344253350053, : number of columns of result is not a multiple of vector
#> length (arg 4)
Removing the missing will work:
sum_stats <- with(df[!is.na(df$salinity) ,] , tapply(salinity, species, summary))
sum_data_table<-data.frame(do.call("rbind", sum_stats))
Or you could try using bind_rows from dplyr instead if you would like a summary of the missingness as well.
library(dplyr)
sum_data_table<-data.frame(do.call(dplyr::bind_rows, sum_stats))