I have to find all values in column1 that have transacted in all distinct values in column2. For ex:
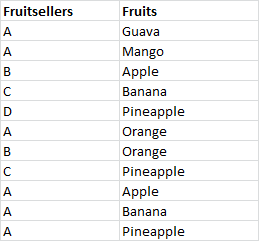
From the above table we can identify the Fruitseller 'A' sells all the fruits.
CodePudding user response:
You can reshape values by crosstab first and then filter all index values if not 0 by boolean indexing:
df1 = pd.crosstab(df['Fruitsellers'], df['Fruits'])
out = df1.index[df1.ne(0).all(axis=1)].tolist()
print (out)
['A']
CodePudding user response:
>>> df
Fruitsellers Fruits
0 A Guava
1 A Mango
2 B Apple
3 C Banana
4 D Pineapple
5 A Orange
6 B Orange
7 C Pineapple
8 A Apple
9 A Banana
10 A Pineapple
>>> filetr_func = lambda x:sorted(x.Fruits.unique()) == sorted(df.Fruits.unique())
>>> (df
... .groupby("Fruitsellers")
... .apply(filetr_func)
... .where(lambda x:x==True)
... .dropna()
... .index
... .to_list()
... )
['A']
CodePudding user response:
Try:
>>> df.drop_duplicates().value_counts('Fruitsellers').eq(df['Fruits'].nunique()) \
.loc[lambda x: x].index.tolist()
# Output:
['A']
Assume in the Fruits column at least one instance is present.
drop_duplicates is not mandatory if you are sure, you have not multiple same rows of (Fruitsellers, Fruits) like 2 x ('A', 'Mango').