I have a df:
df = pd.DataFrame.from_dict({'category': {1050: 'Dining',
992: 'Dining',
1054: 'Kitchen',
1052: 'Kitchen',
993: 'Living room',
980: 'Living room',
996: 'Dining',
1017: 'Dining',
1020: 'Bath',
1001: 'Bath'},
'subcategory': {1050: 'Chairs',
992: 'Chairs',
1054: 'Stool',
1052: 'Mirror',
993: 'mirror',
980: 'chair',
996: 'Chairs',
1017: 'Chairs',
1020: 'Table',
1001: 'Table'},
'discount': {1050: '30-40',
992: '30-40',
1054: '30-40',
1052: '30-40',
993: '30-40',
980: '30-40',
996: '30-40',
1017: '30-40',
1020: '30-40',
1001: '30-40'},
'sales_1': {1050: 9539.86,
992: 12971.86,
1054: 6736.53,
1052: 7163.16,
993: 8601.16,
980: 8047.16,
996: 16322.0,
1017: 14424.32,
1020: 6319.58,
1001: 4551.42},
'sales_2': {1050: 3226.0,
992: 11117.0,
1054: 1613.0,
1052: 2166.0,
993: 11117.0,
980: 3442.0,
996: 19365.0,
1017: 3323.0,
1020: 1411.0,
1001: 572.0}})
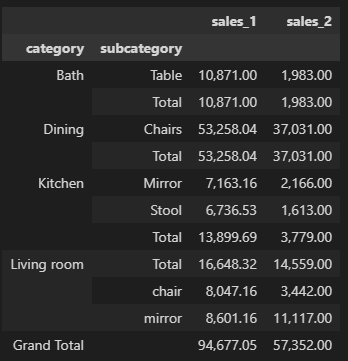
I am trying to add a subtotal in multiindex. I am able to add it with 2 groups like so:
dd = df_from_dict.groupby(['category', 'subcategory'])[['sales_1', 'sales_2']].sum()
s = dd.groupby(level=0).sum()
s.index = pd.MultiIndex.from_product([s.index, ['Total']])
dd = dd.append(s).sort_index()
dd.loc['Grand Total', :] = dd.sum().values / 2
dd
But when I add 3rd item to the group, discount
dd = df_from_dict.groupby(['category', 'subcategory','discount'])[['sales_1', 'sales_2']].sum()
s = dd.groupby(level=0).sum()
s.index = pd.MultiIndex.from_product([s.index, ['Total']])
dd = dd.append(s).sort_index()
dd.loc['Grand Total', :] = dd.sum().values / 2
dd
All of a sudden I get tuples instead of normal multiindex. Instead of 3 indexes I get 1 as a tuple:
Whereas I want the same structure as in the first picture but with another level of index. I tried playing with level=1 parameter in group by but it always ends up in a single index as a tuple, I am not sure where is my mistake.
CodePudding user response:
Here is problem in Series called s are 2 levels MultiIndex, in dd are 3 levels, so in append are created tuple.
Solution is set 3 levels MultiIndex in MultiIndex.from_product, so same number levels like dd and solution working correct:
For avoid sorting all another level in DataFrame.sort_index add sort_remaining=False:
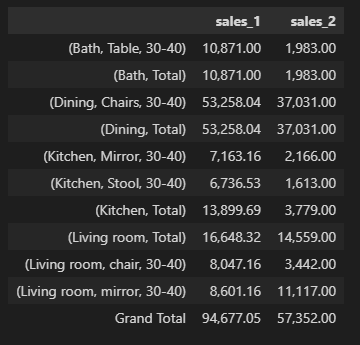
dd = df_from_dict.groupby(['category', 'subcategory','discount'])[['sales_1', 'sales_2']].sum()
s = dd.groupby(level=0).sum()
s.index = pd.MultiIndex.from_product([s.index, ['Total'], ['']])
print (s)
dd = dd.append(s).sort_index(level=0, sort_remaining=False)
dd.loc['Grand Total', :] = dd.sum().values / 2
print (dd)
sales_1 sales_2
category subcategory discount
Bath Table 30-40 10871.00 1983.0
Total 10871.00 1983.0
Dining Chairs 30-40 53258.04 37031.0
Total 53258.04 37031.0
Kitchen Mirror 30-40 7163.16 2166.0
Stool 30-40 6736.53 1613.0
Total 13899.69 3779.0
Living room chair 30-40 8047.16 3442.0
mirror 30-40 8601.16 11117.0
Total 16648.32 14559.0
Grand Total 94677.05 57352.0