Suppose I have the following text:
Yes: [x]
Yes: [ x]
Yes: [x ]
Yes: [ x ]
No: [x
No: x]
I am interested in a regex expression with two capturing groups as follows:
group
$1: match the brackets[and]that contain anxin between with a variable amount of horizontal space aroundx. I can use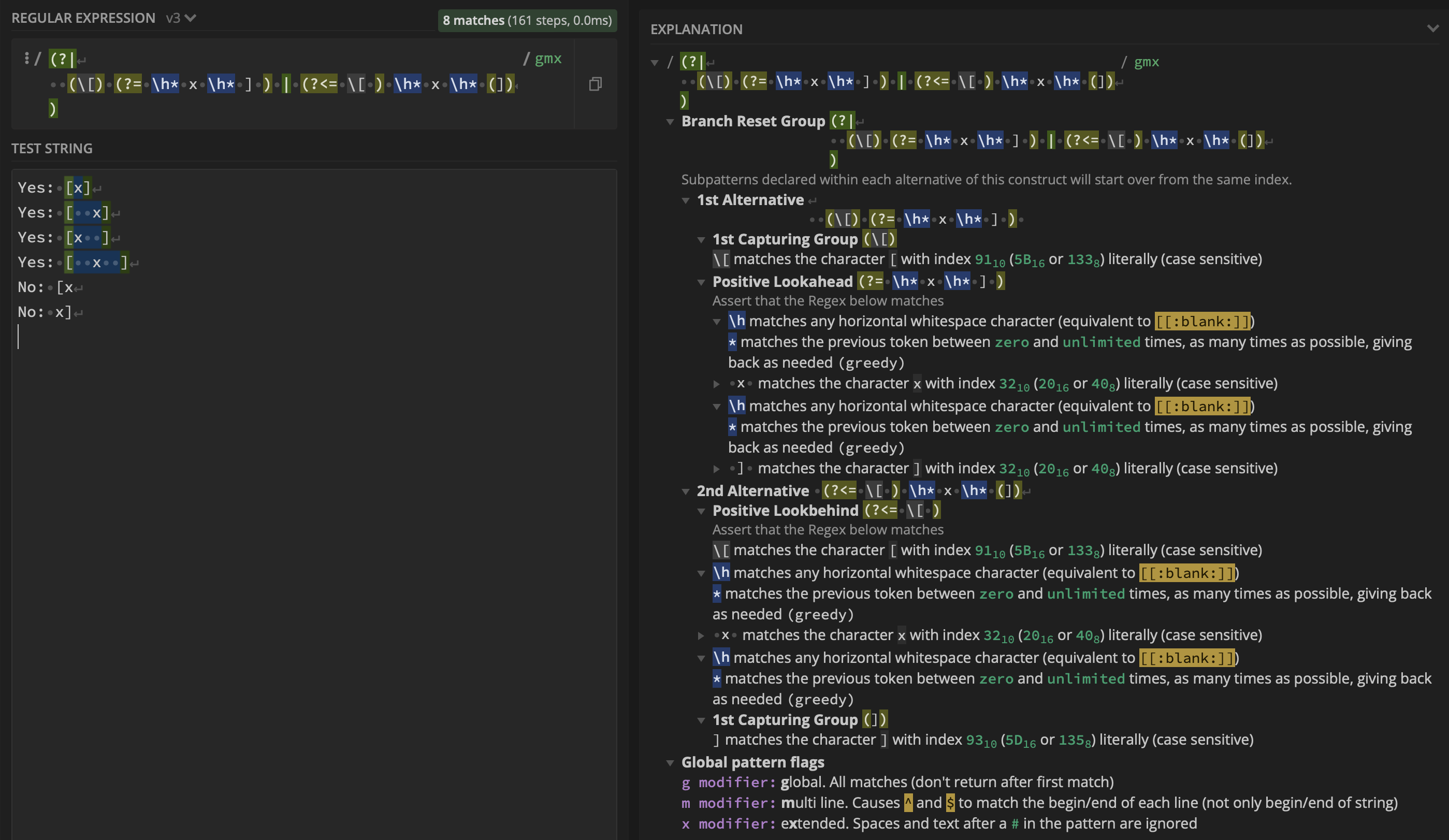
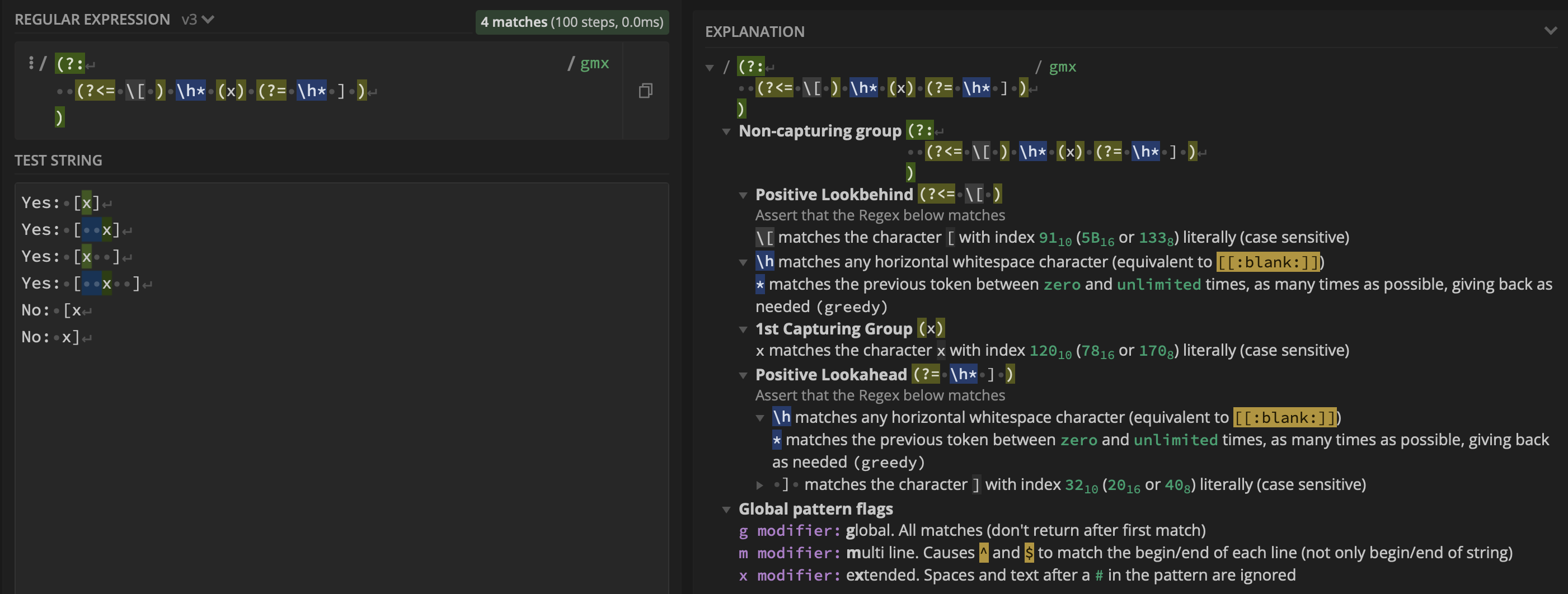
group $2: should match the x that is contained in the brackets [ and ]. For this, I can use a non-capturing group with a combination of positive lookbehind and lookahead assertions:
regex:(?:(?<=\[)\h*(x)(?=\h*]))which results in:
The problem is that when I try to join the expressions by OR, the second expression does not match anything. For example:
(?|(\[)(?=\h*x\h*])|(?<=\[)\h*x\h*(]))|(?:(?<=\[)\h*(x)(?=\h*]))
Results in (i.e., see 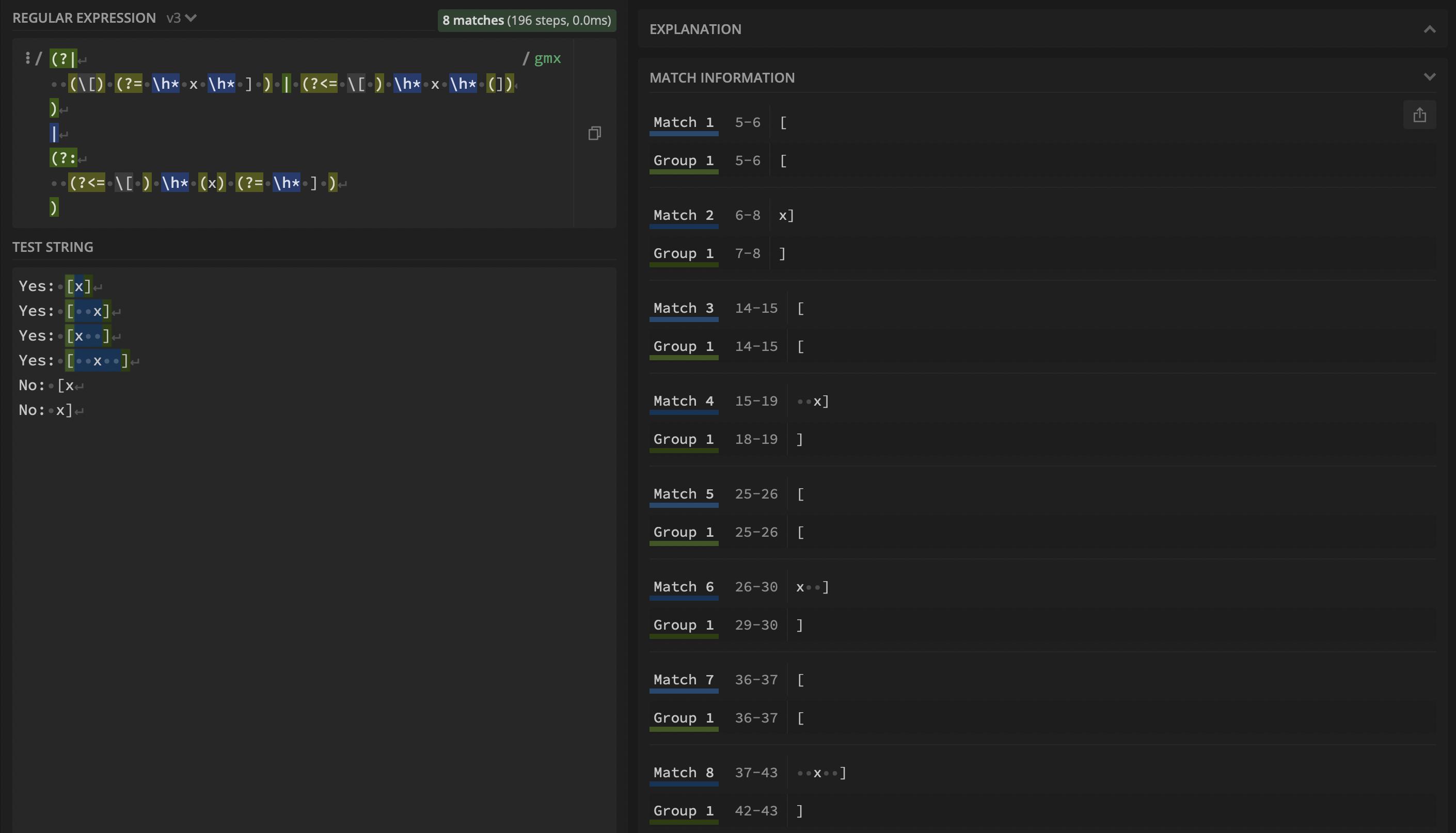
My intuition (i.e., perhaps not correct) is that there is no x left to match for the second expression because the x is matched in the first expression (i.e., group $0). For example, simplifying the second expression to (?:(x)) (i.e., see 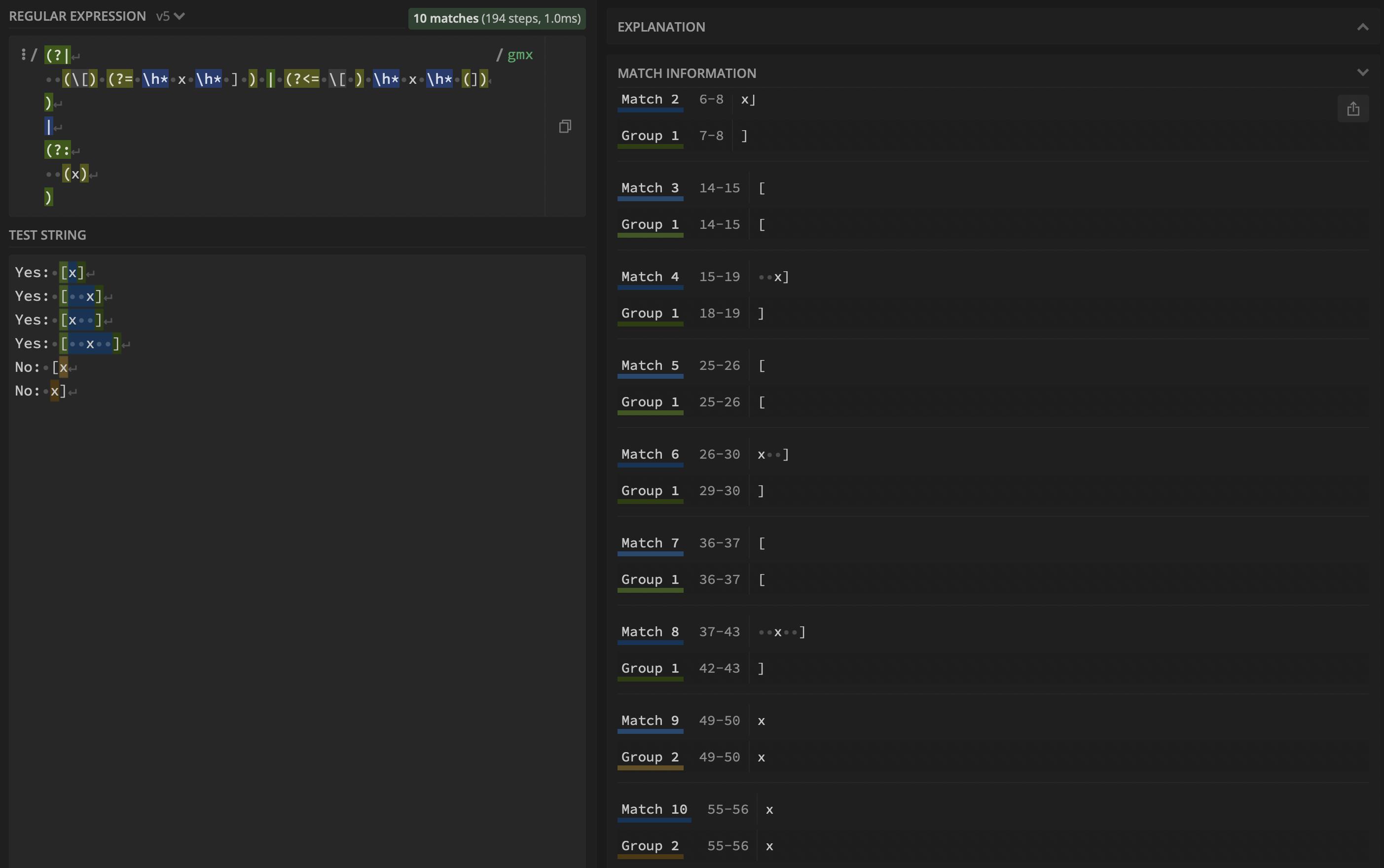
Therefore, I thought I should somehow reset the group $0 matches from the first expression. So I tried adding the \K meta escape to the first expression before (]), but that did not solve anything.
Also, as much as possible, I want to stick to the format (?|regex)|(?:regex)|... because I want to be able to extend the expression further with other groups. I am using Oniguruma regular expressions and the PCRE flavor. Do you have any ideas on how this can be accomplished?
P.S. Apologies if the title of the question is not entirely accurate.
CodePudding user response:
The main issue is that x is already consumed with \h*x\h*(]) part in the first alternative, and \h*(x) in the second alternative cannot re-match what has already been consumed.
If you put the second alternation in the branch reset group inside a lookahead you can "free up" the x for the second alternative to catch it:
(?|
(\[) (?= \h* x \h* ] ) | (?<= \[ )(?= \h* x \h* (])) # <--- here
)
|
(?:
(?<= \[ ) \h* (x) (?= \h* ] )
)
See the regex demo. Pay attenation to the (?=\h*x\h*(])) part: it is now a positive lookahead that only checks for its pattern match immediately on the right, but does not put the matched text to the match value buffer and does not advance the regex index, so that subsequent subpatterns can try to match their patterns against this text.
To accommodate for further alternatives, make sure you use this technique: try to match as close to the start of string as possible, and only consume text that does not have to be rematched, else, use positive lookaheads with capturing groups in them.