Hi I have the following DataFrame:
from datetime import datetime as dt
import numpy as np
import pandas as pd
inputs = {
'indicator':[69.88, 85.05, 50.19, 71.08, 44.83, 36.32, 29.42, 44.47, 34.71, 37.91, 32.78, 35.85, 38.98, 23.16, 73.22, 77.77, 49.22, 59.1, 83.38, 88.5, 47.78],
'short_trade':[0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0],
'pnl':[-0.0, -0.0, 0.05, -0.06, 0.05, 0.0, 0.0, -0.0, 0.0, -0.0, 0.0, -0.0, -0.0, 0.0, -0.0, -0.0, 0.01, -0.0, -0.0, -0.01, 0.03]
}
_idx = pd.date_range('2018-08-10','2018-09-09',freq='D').to_series()
_idx = _idx[_idx.dt.dayofweek < 5]
data = pd.DataFrame(inputs, index = _idx)
data
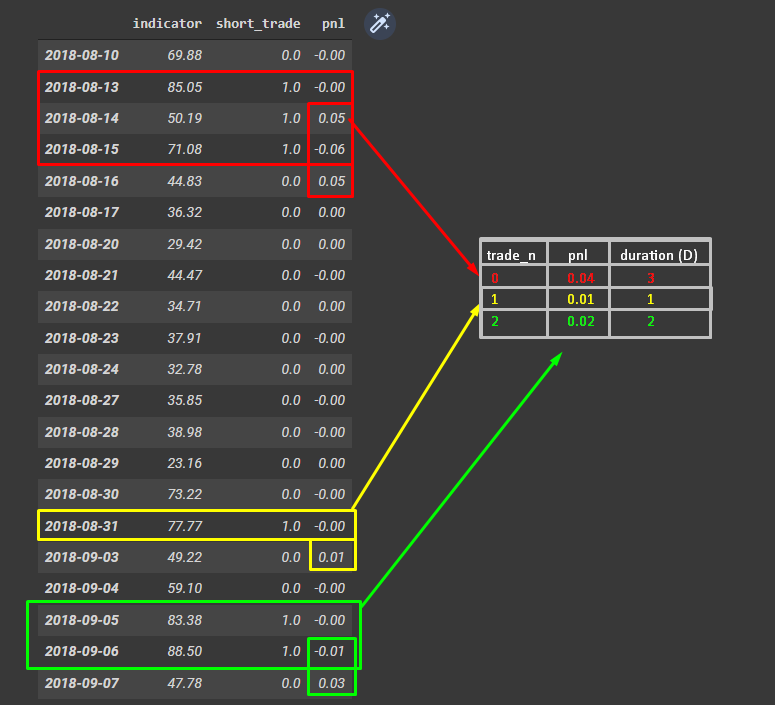
My goal is to create a new DataFrame as shown in the screenshot below. Grouping when short_trade != 0 or pnl != 0 (it's the same thing).
The first column of the new DataFrame (trade_n) is just an Id for each different trade. The new column pnl is the sum for each group from the initial DataFrame. Lastly, duration (D) is the number of days each trade lasted.
Can't find a way to do it with pandas/numpy. I have found a workaround looping through the DataFrame and checking each row but I'm pretty sure there's a more efficient solution using pandas/numpy. Any help will be appreciated.
CodePudding user response:
IIUC:
m = df.short_trade.ne(0) | df.pnl.ne(0)
g = mask.eq(True) & mask.shift().eq(False)
out = df.assign(trade_n=g.cumsum().sub(1)[m]).groupby('trade_n') \
.agg(**{'pnl': ('pnl', lambda x: sum(x[x.ne(0)])),
'duration (D)': ('short_trade', lambda x: len(x.ne(0)))}) \
.reset_index().astype({'trade_n': int})
Output:
>>> out
trade_n pnl duration (D)
0 0 0.04 4
1 1 0.01 2
2 2 0.02 3
CodePudding user response:
Try this:
s = df \
.groupby((df['short_trade'].astype(bool) | df['short_trade'].shift(1)).diff().cumsum()) \
.apply(lambda x: [x.shape[0] - 1, x['pnl'].tolist()]) \
[::2] \
.reset_index(drop=True) \
.tolist()
df = pd.DataFrame(s, columns=['duration (D)', 'pnl']) \
.reset_index() \
.rename({'index': 'trade_n'}, axis=1)
Output:
>>> df
trade_n duration (D) pnl
0 0 3 [-0.0, 0.05, -0.06, 0.05]
1 1 1 [-0.0, 0.01]
2 2 2 [-0.0, -0.01, 0.03]