I have a df2 and a temp df that has more rows and more columns(some are common) than df2.
df2=pd.DataFrame(data=(['False','False',0.9],['False','True', 0.1],['True','False',0.2],['True','True',0.8]), columns=['Winter?','Sprinkler?', 'Rain?'] )
temp=pd.DataFrame(list(itertools.product([False, True], repeat=len(['Winter?','Sprinkler?', 'Rain?']))),columns=['Winter?','Sprinkler?', 'Rain?'])
temp["p"] = np.nan
I want to get the 'p'col values from df2 into temp df, in the rows with compatible values between the two (see screenshot below.)
so expected output would be the following df:
output_df = pd.DataFrame(list(itertools.product([False, True], repeat=len(['Winter?','Sprinkler?', 'Rain?']))),columns=['Winter?','Sprinkler?', 'Rain?'])
output_df["p"] = [0.9, 0.1, 0.9, 0.1, 0.2, 0.8, 0.2, 0.8]
This should not be as hard as I'm finding it, I understand that dataframes thrive for these kind of stuff but I have been stuck for quite some days so any help would be much 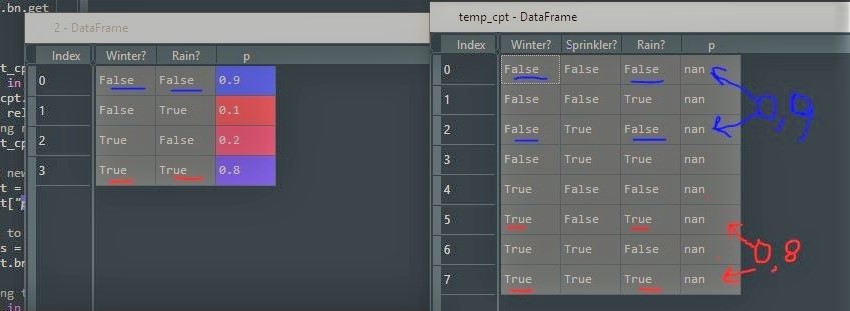 appreciated
appreciated
CodePudding user response:
Use merge:
temp = temp.drop(columns='p').merge(df2, on=['Winter?', 'Rain?'], how='left')
print(temp)
# Output:
Winter? Sprinkler? Rain? p
0 False False False 0.9
1 False False True 0.1
2 False True False 0.9
3 False True True 0.1
4 True False False 0.2
5 True False True 0.8
6 True True False 0.2
7 True True True 0.8
Note: I dropped the column p from temp because it's not necessary.
I slightly modified your dataframe df2. If you want to merge data, you must have the same dtype between columns. In your sample, Winter and Rain of df2 are strings while Winter and Rain of temp are booleans.
Setup:
df2 = pd.DataFrame({'Winter?': [False, False, True, True],
'Rain?': [False, True, False, True],
'p': [0.9, 0.1, 0.2, 0.8]})