I'm trying to calculate StartDate and EndDate based on a date column from a table. Below is the source table looks like
Scenario 1
| ID | SERIAL_NUMBER | STATUS | READ_DT |
|---|---|---|---|
| 123456789 | 42007 | D | 15-12-2021 |
| 123456789 | 42007 | D | 16-12-2021 |
| 123456789 | 42007 | D | 17-12-2021 |
| 123456789 | 42007 | D | 18-12-2021 |
| 123456789 | 42007 | D | 19-12-2021 |
| 123456789 | 42007 | D | 20-12-2021 |
| 123456789 | 42007 | D | 21-12-2021 |
I want to calculate start_date and end_date based on READ_DT, for a ID and SERIAL_NUMBER if all READ_DT are available then the output should be as below
| ID | SERIAL_NUMBER | STATUS | Start_Date | End_Date |
|---|---|---|---|---|
| 123456789 | 42007 | D | 15-12-2021 | 21-12-2021 |
Scenario 2
| ID | SERIAL_NUMBER | STATUS | READ_DT |
|---|---|---|---|
| 123456789 | 42007 | D | 15-12-2021 |
| 123456789 | 42007 | D | 16-12-2021 |
| 123456789 | 42007 | D | 17-12-2021 |
| 123456789 | 42007 | D | 19-12-2021 |
| 123456789 | 42007 | D | 20-12-2021 |
| 123456789 | 42007 | D | 21-12-2021 |
If there is any gap present in between READ_DT then expected output should be in two transactions as below.
| ID | SERIAL_NUMBER | STATUS | Start_Date | End_Date |
|---|---|---|---|---|
| 123456789 | 42007 | D | 15-12-2021 | 17-12-2021 |
| 123456789 | 42007 | D | 19-12-2021 | 21-12-2021 |
CodePudding user response:
A little sequential temporal math makes short work of these things.
--===== This will work for either scenario
WITH cteDTgrp AS
(--==== Subtract an increasing number of days from each date to create the date groups.
SELECT *
,DT_Grp = DATEADD(dd,-ROW_NUMBER() OVER (PARTITION BY ID,SERIAL_NUMBER,STATUS ORDER BY READ_DT),READ_DT)
FROM dbo.YourTableNameHere
)--==== Then the grouping to get the start and end dates is trivial.
SELECT ID,SERIAL_NUMBER,STATUS
,Start_Date = MIN(READ_DT)
,End_Date = MAX(READ_DT)
FROM cteDTgrp
GROUP BY ID,SERIAL_NUMBER,STATUS,DT_Grp --<----This is the key!
ORDER BY ID,SERIAL_NUMBER,STATUS,Start_Date
;
Note that this will only work if the READ_DT is unique for each group of ID,SERIAL_NUMBER,STATUS.
CodePudding user response:
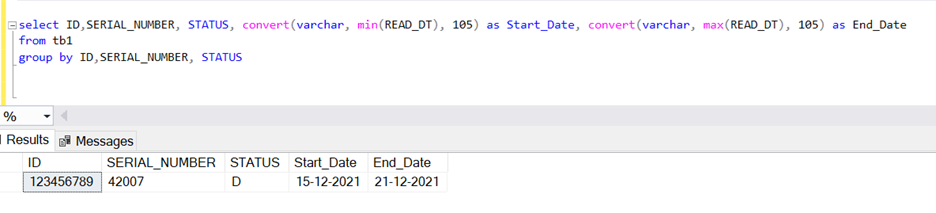
For scenario 1 you can direct use aggregate min and max functions group by remaining columns.
select ID,SERIAL_NUMBER, STATUS, convert(varchar, min(READ_DT), 105) as Start_Date, convert(varchar, max(READ_DT), 105) as End_Date
from tb1
group by ID,SERIAL_NUMBER, STATUS
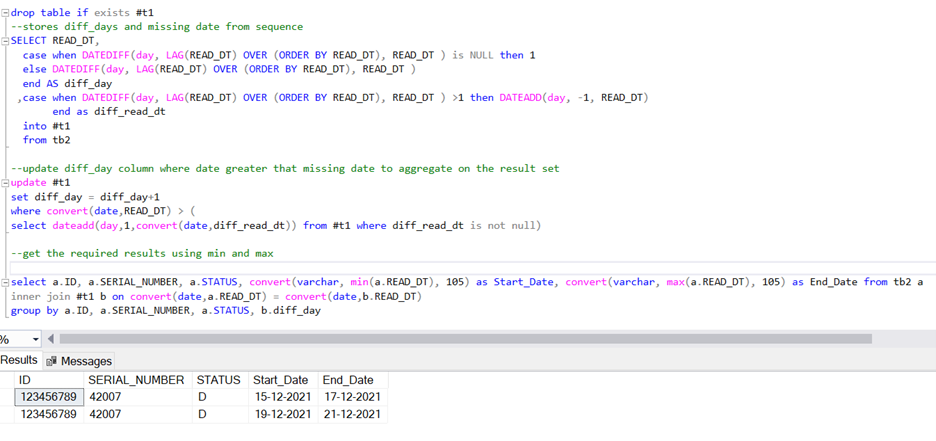
For Scenario 2, I used the LAG function to get the difference of date of the current row compared to the previous row and performed aggregation after that.
This code worked for scenarios 1 & 2 data.
Code:
drop table if exists #t1
--stores diff_days and missing date from sequence
SELECT READ_DT,
case when DATEDIFF(day, LAG(READ_DT) OVER (ORDER BY READ_DT), READ_DT ) is NULL then 1
else DATEDIFF(day, LAG(READ_DT) OVER (ORDER BY READ_DT), READ_DT )
end AS diff_day
,case when DATEDIFF(day, LAG(READ_DT) OVER (ORDER BY READ_DT), READ_DT ) >1 then DATEADD(day, -1, READ_DT)
end as diff_read_dt
into #t1
from tb2
--update diff_day column where date greater that missing date to aggregate on the result set
update #t1
set diff_day = diff_day 1
where convert(date,READ_DT) > (select dateadd(day,1,convert(date,diff_read_dt)) from #t1 where diff_read_dt is not null)
--get the required results using min and max
select a.ID, a.SERIAL_NUMBER, a.STATUS, convert(varchar, min(a.READ_DT), 105) as Start_Date, convert(varchar, max(a.READ_DT), 105) as End_Date
from tb2 a
inner join #t1 b on convert(date,a.READ_DT) = convert(date,b.READ_DT)
group by a.ID, a.SERIAL_NUMBER, a.STATUS, b.diff_day