I am using Spark SQL 3.2.0
Please see the 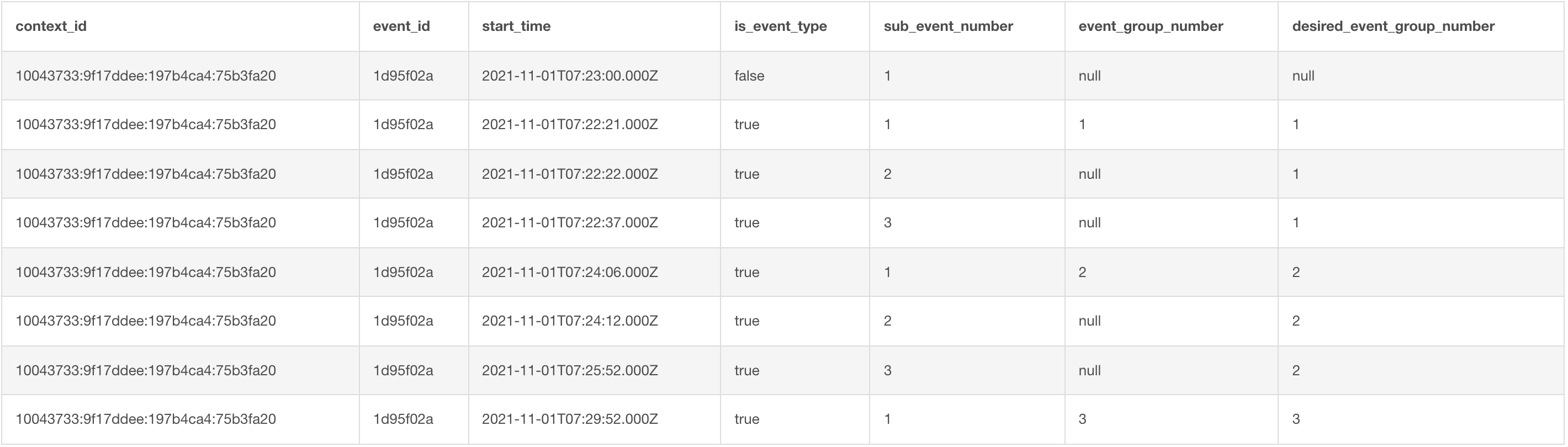
In abstract, I have a dataset with a series of related events that can be grouped by their time order and event number. When ordering by time and event number, every time the event number resets to 1, you're looking at a new set of events.
I understand how to use row_number() or dense_rank() to increment event_group_number where sub_event_number = 1, but I'm uncertain how to make the rows where sub_event_number > 1 take on the correct event_group_number.
I'm currently doing the following:
case
when sub_event_number = 1 and is_event_type
then row_number() over (partition by context_id, event_id, sub_event_number order by is_event_type asc, start_time asc) - 1
else null
end as event_group_number
I'd be grateful for any help, and I'm happy to answer any questions.
CodePudding user response:
It seems you're looking for a cumulative conditional sum:
SELECT context_id,
event_id,
start_time,
NULLIF(
SUM(CASE WHEN sub_event_number = 1 THEN 1 ELSE 0 END) OVER(
PARTITION BY context_id, event_id
ORDER BY is_event_type, start_time) - 1,
0
) AS event_group_number
FROM foobar
ORDER BY context_id, event_id, is_event_type, start_time