A shortened version of my dataframe looks like this:
df_crop = pd.DataFrame({
'Name' : ['Crop1', 'Crop1', 'Crop1', 'Crop1', 'Crop2', 'Crop2', 'Crop2', 'Crop2'],
'Type' : ['Area', 'Diesel', 'Fert', 'Pest', 'Area', 'Diesel', 'Fert', 'Pest'],
'GHG': [14.9, 0.0007, 0.145, 0.1611, 2.537, 0.011, 0.1825, 0.115],
'Acid': [0.0125, 0.0005, 0.0029, 0.0044, 0.013, 0.00014, 0.0033, 0.0055],
'Terra Eutro': [0.053, 0.0002, 0.0077, 0.0001, 0.0547, 0.00019, 0.0058, 0.0002]
})
I now need to normalise all values in the dataframe with yield, which is different per crop, but not per Type:
s_yield = pd.Series([0.388, 0.4129],
index=['Crop1', 'Crop2'])
I need to preserve the information in 'Type'. If I try to use .mul() I receive an error due to the duplicated indices: ValueError: cannot reindex from a duplicate axis.
The only other idea I have is using .loc() but I have a lot of columns (16 with values to normalise) and nothing efficient came to mind. Any suggestions?
Edit:
The following table might help to show what I try to achieve:
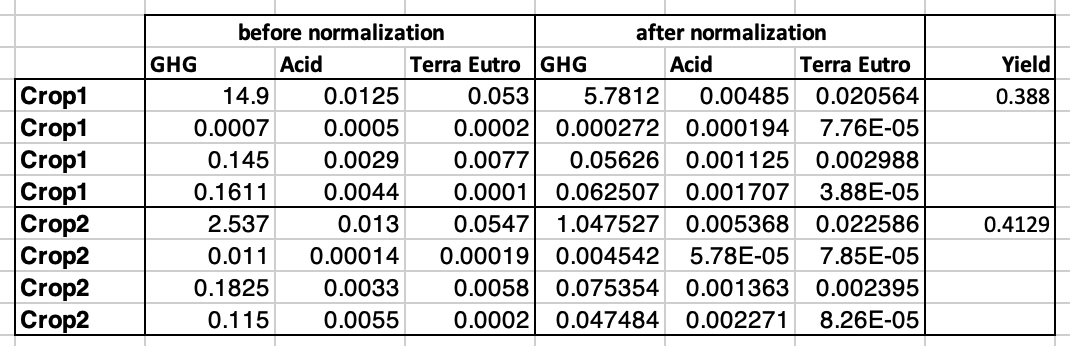
CodePudding user response:
Get the numeric data and multiply using the series
numeric_df = df_crop.select_dtypes('number')
df_crop[numeric_df.columns] = numeric_df.mul(df_crop.Name.map(s_yield), axis=0)
Output
Name Type GHG Acid Terra Eutro
0 Crop1 Area 5.781200 0.004850 0.020564
1 Crop1 Diesel 0.000272 0.000194 0.000078
2 Crop1 Fert 0.056260 0.001125 0.002988
3 Crop1 Pest 0.062507 0.001707 0.000039
4 Crop2 Area 1.047527 0.005368 0.022586
5 Crop2 Diesel 0.004542 0.000058 0.000078
6 Crop2 Fert 0.075354 0.001363 0.002395
7 Crop2 Pest 0.047483 0.002271 0.000083
CodePudding user response:
Starting from pandas 0.24.0 you can merge series to a dataframe directly as long as the series is named:
df_merged = df_crop.merge(s_yield.rename('yield'), left_on = 'Name', right_index = True)
then multiply columns as needed.
CodePudding user response:
You can use s_yield.map to extend the Series to the length of the dataframe, and you can use df.select_dtypes to find all the columns of a specific dtype(s) and multiple on them:
cols = df_crop.select_dtypes('number').columns
df_crop[cols] = df_crop[cols].mul(df_crop['Name'].map(s_yield), axis=0)
Output:
>>> df_crop
Name Type GHG Acid Terra Eutro
0 Crop1 Area 5.781200 0.004850 0.020564
1 Crop1 Diesel 0.000272 0.000194 0.000078
2 Crop1 Fert 0.056260 0.001125 0.002988
3 Crop1 Pest 0.062507 0.001707 0.000039
4 Crop2 Area 1.047527 0.005368 0.022586
5 Crop2 Diesel 0.004542 0.000058 0.000078
6 Crop2 Fert 0.075354 0.001363 0.002395
7 Crop2 Pest 0.047483 0.002271 0.000083