I have a simple data frame with one column SIZE of categorical values (SMALL, MEDIUM, LARGE) and another column VALUE of integers. When I create a scatter plot of VALUE as a function of SIZE, the order of the categories shown on the X axis will change, depending on the SIZE of the first row in the dataframe. I made sure to tell Pandas the explicit "ordering" of the SIZE category values.
To see this in action, use the following code snippet
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({'SIZE': ['MEDIUM', 'MEDIUM', 'LARGE', 'SMALL', 'LARGE', 'LARGE'],
'VALUE': [1, 2, 3, 4, 5, 6]})
# Convert to categorical data type and define the order
df['SIZE'] = pd.Categorical(df['SIZE'], categories=['SMALL', 'MEDIUM', 'LARGE'], ordered=True)
print(df.dtypes)
print(df)
print(df.SIZE.describe)
This produces the following output:
SIZE category
VALUE int64
dtype: object
SIZE VALUE
0 MEDIUM 1
1 MEDIUM 2
2 LARGE 3
3 SMALL 4
4 LARGE 5
5 LARGE 6
<bound method NDFrame.describe of 0 MEDIUM
1 MEDIUM
2 LARGE
3 SMALL
4 LARGE
5 LARGE
Name: SIZE, dtype: category
Categories (3, object): ['SMALL' < 'MEDIUM' < 'LARGE']>
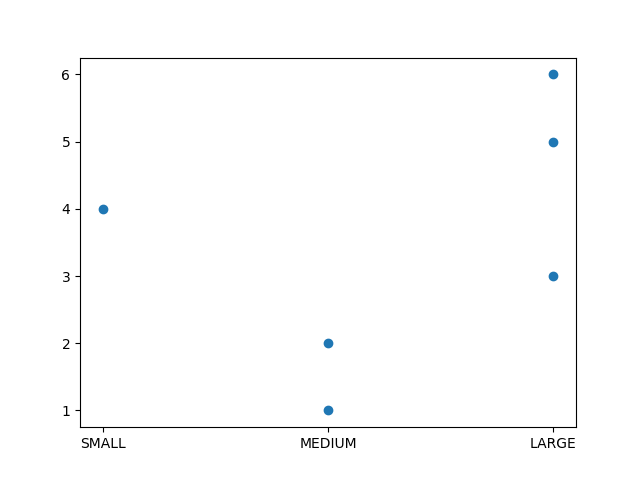
Looking at this, it appears that all is well. But when I plot using
fig, ax = plt.subplots()
ax.scatter(df.SIZE, df.VALUE)
I get a graph where the first category on the X axis is 'MEDIUM', not 'SMALL'.
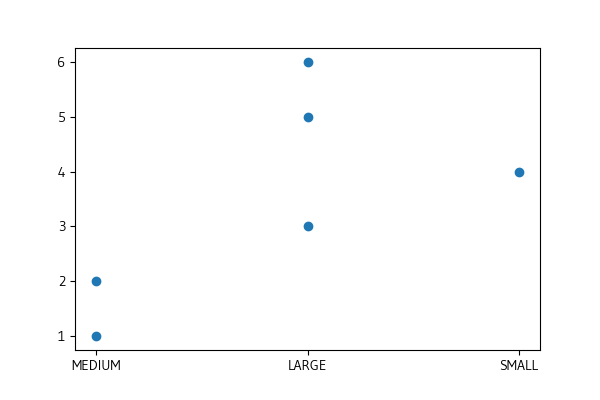
If I simply change the SIZE of the first row to 'SMALL', i.e.
df = pd.DataFrame({'SIZE': ['SMALL', 'MEDIUM', 'LARGE', 'SMALL', 'LARGE', 'LARGE'],
'VALUE': [1, 2, 3, 4, 5, 6]})
and rerun the rest of the code I'll get a graph that has the proper order.
I'm apparently missing some nuance in Matplotlib. I'm using Matplotlib 3.4.3 and Pandas 1.3.4.
CodePudding user response:
Matplotlib doesn't care about Categorical dtype. You should sort your dataframe first by SIZE:
fig, ax = plt.subplots()
df = df.sort_values('SIZE')
ax.scatter(df.SIZE, df.VALUE)
plt.show()