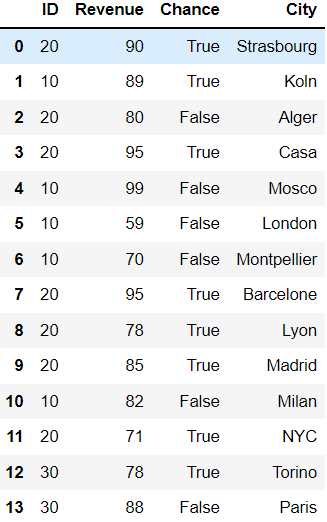
Let's say we have the following dataframe:
df = pd.DataFrame({"ID": [20, 10, 20, 20, 10, 10, 10, 20, 20, 20, 10, 20, 30, 30],
"Revenue": [90, 89, 80, 95, 99, 59, 70, 95, 78, 85, 82, 71, 78, 88],
"Chance": [True, True, False, True, False, False, False, True, True, True, False, True, True, False],
"City": ["Strasbourg", "Koln", "Alger", "Casa", "Mosco", "London", "Montpellier", "Barcelone", "Lyon", "Madrid", "Milan", "NYC", "Torino", "Paris"]
})
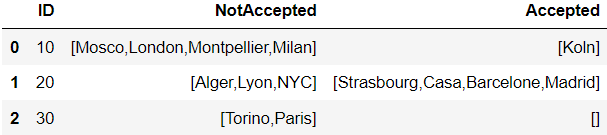
The df should be grouped by ID and 2 columns should be created as follows:
-'NotAccepted' cities: cities which have: 'Revenue' below 84 OR 'Chance' is False:
-'Accepted' cities are the rest.
I have to concatenate the names of all 'Accepted' and 'NotAccepted' cities into these columns. (Please check the final photo below)
My solution is as follows:
df_result=df.groupby('ID').apply(lambda g: pd.Series({
'NotAccepted': [','.join(g['City'][(g['Chance'] == False) | (g['Revenue'] < 84)])],
'Accepted': [','.join(g['City'][(g['Chance'] == True) & (g['Revenue'] >= 84)])],
})).reset_index()
The real df is actually large and takes a long time to group/apply. Is there a faster alternative than my solution? Thank you.
CodePudding user response:
You can just build a col before groupby
df['new'] = np.where((df['Chance'] == False) | (df['Revenue'] < 84),'NotAccepted','Accepted')
out = df.groupby(['ID','new'])['City'].agg(list).unstack(fill_value=[])
CodePudding user response:
Use Dask Groupby - I faced a similar issue and received about 1 order of magnitude speedup. This allows you to run across multiple CPUs rather than being single-thread bound.
https://examples.dask.org/dataframes/02-groupby.html
I would imagine there are ways to send to GPU/multi-node as well.