Using the Linux command df -Ph > metric.csv to create this output:
Filesystem Size Used Avail Use% Mounted on
udev 3.9G 0 3.9G 0% /dev
tmpfs 786M 2.2M 783M 1% /run'''
I login to postgres and CREATE TABLE:
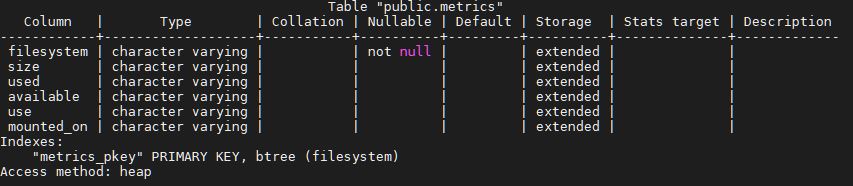
CREATE TABLE metric(filesystem varchar,size varchar,used
varchar,available varchar,use varchar,mounted_on varchar, PRIMARY
KEY(filesystem));
Next I'm using the COPY command to insert data into this table:
COPY metrics (filesystem,size,used,available,use,mounted_on) FROM '/data/metric.csv' CSV HEADER DELIMITER ',';
I'm getting the following error:
ERROR: missing data for column "size"
CONTEXT: COPY metrics, line 2: "udev 3.9G 0 3.9G 0% /dev"
I'd appreciate any help or advice as to how to correct this so I can insert my data into the database.
CodePudding user response:
You may want to try this:
df -Ph | awk 'BEGIN{OFS=","}NR>1{$1=$1; print}' > metric.csv
As I mentioned in the comment above, your csv file isn't a csv. The awk command gets rid of the "header" (which I assume you don't want ingested in the table) and replaces the spaces with commas.
A few explanatory words regarding the awk - statement.
In the BEGIN{} section processing takes place before awk actually tackles any input. What we tell awk here to use , as the output field separator (OFS). By default awk uses any number of consecutive whitespace.
NR>1 tells awk to skip the first line (NR == number of record), thus omitting the header.
{$1=$1;print} - the assigning of the first field to itself is unfortunately necessary for awk to process the line; the print just does exactly what you think it does.