I'm currently facing a wall regarding merging data I extracted with beautifulsoup, I'm unfortunately don't know how to figure out this issue.
Actually, I'm looking to get for each bar code contained in table as html, the detailled products. Knowing that on each page I parse I can have more than one bar code.
below the code :
import requests
from bs4 import BeautifulSoup
###################_____Parameter_____###################
url = 'https://rappel.conso.gouv.fr'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
#########################################################
#Collecting links on rappel.gouv
def get_soup(url):
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
return soup
def extract_product_urls(url):
links = [url x['href'] for x in get_soup(url).select('a.product-link')]
return links
soup = get_soup(url)
url_data = extract_product_urls(url)
#Collecting data on each url collected
def data(url_data):
data_set = []
#Collecting bar_code
for row in url_data:
req_bar = requests.get(row, headers=headers)
ext_bar = BeautifulSoup(req_bar.text, 'html.parser')
for code_bar in ext_bar.find_all('tbody', {'class' : 'text-left'}):
table_content_tr = code_bar.findAll('tr')
for td in table_content_tr:
all_data = td.findAll('td')
all_data = [x.text.strip() for x in all_data]
#collecting detailled products
for data in url_data:
req = requests.get(data, headers=headers)
ext = BeautifulSoup(req.text, 'html.parser')
for products in ext.find_all('div', {'class' : 'row site-wrapper'}):
title = products.find('p', {'class' : 'h5 product-main-title'}).text
brand = products.find('p', {'class' : 'text-muted product-main-brand'}).text.replace('\xa0:\n',': ').strip()
category = products.find('p', {'class' : 'product-cat'}).text
detail_rappel = products.find_all('div', {'class' : 'card product-practical'})
for motif in detail_rappel:
val_1 = motif.find('span', {'class': 'val'}).text
results = *all_data, title, brand, category, val_1
data_set.append(results)
return data_set
#final result
final = data(url_data)
for i in final:
print(i)
This is the actual result I get :
('8712364296389', 'Tous les lots', 'BOUQUET GARNI POT AU FEU BIOLOGIQUE', 'Marque: LES HERBES DE MON PERE', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('8712364296389', 'Tous les lots', 'BOUILLOTTE DE NOEL', 'Marque: NOCIBE', 'Divers', 'Risque de bouillotte défectueuse pouvant entraîner risque de sécurité du consommateur lors du réchauffage des bouillottes par micro-ondes (brûlures et
incendie) ')
('8712364296389', 'Tous les lots', 'BOTTE THYM', 'Marque: Sans marque', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('8712364296389', 'Tous les lots', 'BOTTE THYM BIOLOGIQUE', 'Marque: Sans marque', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('8712364296389', 'Tous les lots', 'Rôti de porc farci', 'Marque: Sans Marque', 'Viandes', 'Détection de Salmonelle')
('8712364296389', 'Tous les lots', 'Grille Pain TL640810', 'Marque: Tefal', 'Appareils électriques, électroménager', 'Risque de choc électrique ')
('8712364296389', 'Tous les lots', 'Coppa vendue en tranche au rayon Coupe', 'Marque: Sans marque', 'Autres', 'Présence de Listeria monocytogenes <10 ufc/g')
('8712364296389', 'Tous les lots', 'JOUETS ARC 25 CM ET 2 FLECHES AVEC VENTOUSE', 'Marque: B&G INTERNATIONAL - BGI', 'Jouets', 'rappel pour une non-conformité sur la solidité de la fixation de la ventouse de la flèche qui ne tient pas
et se détache de la tige')
('8712364296389', 'Tous les lots', 'DEGUISEMENT PETITE SORCIERE PINK WITCH', 'Marque: FIESTAS GUIRCA', 'Articles pour enfants et puériculture', "rappel pour une non-conformité sur la fragilité des coutures des sequins risquant de casser lors d'une trop forte traction")
('8712364296389', 'Tous les lots', 'DEGUISEMENT BEBE LICORNE', 'Marque: FUNNY FASHION', 'Articles pour enfants et puériculture', "rappel concernant le produit pour une non-conformité sur la tirette de la fermeture éclair qui risque de casser lors d'une trop forte pression")
This what I actually want : [expectation result]
('3333313501047', 'F993002', 'Date de durabilité minimale 31/12/2024', 'BOUQUET GARNI POT AU FEU BIOLOGIQUE', 'Marque: LES HERBES DE MON PERE', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('3466762557225', 'M211', '', 'BOUILLOTTE DE NOEL', 'Marque: NOCIBE', 'Divers', 'Risque de bouillotte défectueuse pouvant entraîner risque de sécurité du consommateur lors du réchauffage des bouillottes par micro-ondes (brûlures et incendie) ')
('3466762557232', 'M211', '', 'BOUILLOTTE DE NOEL', 'Marque: NOCIBE', 'Divers', 'Risque de bouillotte défectueuse pouvant entraîner risque de sécurité du consommateur lors du réchauffage des bouillottes par micro-ondes (brûlures et incendie) ')
('3333313131183', 'F21101308407L03', '', 'BOTTE THYM', 'Marque: Sans marque', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('3333313131183', 'F21101308407L04', '', 'BOTTE THYM', 'Marque: Sans marque', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('3333313131183', 'F21101308407L03', '', 'BOTTE THYM BIOLOGIQUE', 'Marque: Sans marque', 'Fruits et légumes', "présence d'un résidu de pesticide interdit")
('', '21355-8810', 'Date limite de consommation 29/12/2021', 'Rôti de porc farci', 'Marque: Sans Marque', 'Viandes', 'Détection de Salmonelle')
('', 'Tous les lots', '', 'Grille Pain TL640810', 'Marque: Tefal', 'Appareils électriques, électroménager', 'Risque de choc électrique ')
('0208465000000', 'Coppa vendue au rayon charcuterie coupe du 09/11/21 au 28/11/21', '', 'Coppa vendue en tranche au rayon Coupe', 'Marque: Sans marque', 'Autres', 'Présence de Listeria monocytogenes <10 ufc/g')
('3588270030394', 'Tous les lots', '', 'JOUETS ARC 25 CM ET 2 FLECHES AVEC VENTOUSE', 'Marque: B&G INTERNATIONAL - BGI', 'Jouets', 'rappel pour une non-conformité sur la solidité de la fixation de la ventouse de la flèche qui ne tient pas et se détache de la tige')
('8434077830369', 'Tous les lots', '', 'DEGUISEMENT PETITE SORCIERE PINK WITCH', 'Marque: FIESTAS GUIRCA', 'Articles pour enfants et puériculture', "rappel pour une non-conformité sur la fragilité des coutures des sequins risquant de casser lors d'une trop forte traction")
('8434077830376', 'Tous les lots', '', 'DEGUISEMENT PETITE SORCIERE PINK WITCH', 'Marque: FIESTAS GUIRCA', 'Articles pour enfants et puériculture', "rappel pour une non-conformité sur la fragilité des coutures des sequins risquant de casser lors d'une trop forte traction")
('8712364296396', 'Tous les lots', '', 'DEGUISEMENT BEBE LICORNE', 'Marque: FUNNY FASHION', 'Articles pour enfants et puériculture', "rappel concernant le produit pour une non-conformité sur la tirette de la fermeture éclair qui risque de casser lors d'une trop forte pression")
('8712364296372', 'Tous les lots', '', 'DEGUISEMENT BEBE LICORNE', 'Marque: FUNNY FASHION', 'Articles pour enfants et puériculture', "rappel concernant le produit pour une non-conformité sur la tirette de la fermeture éclair qui risque de casser lors d'une trop forte pression")
('8712364296389', 'Tous les lots', '', 'DEGUISEMENT BEBE LICORNE', 'Marque: FUNNY FASHION', 'Articles pour enfants et puériculture', "rappel concernant le produit pour une non-conformité sur la tirette de la fermeture éclair qui risque de casser lors d'une trop forte pression")
Also the issue is the following : Each page may have a different table frame : below 3 examples Example 1
<table >
<thead >
<th>GTIN</th>
<th>Lot</th>
</thead>
<tbody >
<tr>
<td colspan="1">
8712364296396
</td>
<td colspan="2">
Tous les lots
</td>
</tr>
<tr>
<td colspan="1">
8712364296372
</td>
<td colspan="2">
Tous les lots
</td>
</tr>
<tr>
<td colspan="1">
8712364296389
</td>
<td colspan="2">
Tous les lots
</td>
</tr>
</tbody>
</table>Example 2 :
<table >
<thead >
<th>Lot</th>
</thead>
<tbody >
<tr>
<td colspan="3">
Tous les lots
</td>
</tr>
</tbody>
</table>Example 3 :
<table >
<thead >
<th>GTIN</th>
<th>Lot</th>
<th>Date</th>
</thead>
<tbody >
<tr>
<td colspan="1">
3333313501047
</td>
<td colspan="1">
F993002
</td>
<td colspan="1">
Date de durabilité minimale 31/12/2024
</td>
</tr>
</tbody>
</table>The main issue is the table in html, I want to consider that all the data have at least "GTIN", "Lot" and "Date" no matter if the data exist or not. If it does not exist then you write an empty space'' (as I written in the expectation result above)
in finally all the data will be put into a mysql database, so I don't know if it's relevant to create columns knowning (with pandas or tabulate) i'm going to create them with mysql connector.
Sorry if it's a bit confusing, english is not my native language :) i'd be glad to answer if you have any questions ^^
CodePudding user response:
This isn't perfect, but I think it will get you what you are looking for. Your first loops through the data to collect GTIN, LOT, and Date is overwriting itself. Look for the "added" and "removed" in the comments. I also have a method of viewing the results commented out. (The code works if you wanted to use it.) I also have two that are not commented out. The last version requires the packaged tabulate. This code requires the packages numpy and re, as well.
I included all of your original code and the changes. Let me know if there's anything I failed to clarify.
import requests
from bs4 import BeautifulSoup
import numpy as np
import re
import tabulate
###################_____Parameter_____###################
url = 'https://rappel.conso.gouv.fr'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
#########################################################
#Collecting links on rappel.gouv
def get_soup(url):
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
return soup
def extract_product_urls(url):
links = [url x['href'] for x in get_soup(url).select('a.product-link')]
return links
soup = get_soup(url)
url_data = extract_product_urls(url)
#Collecting data on each url collected
def data(url_data):
data_set = []
all_data = [] # <-- ADDED
tbler = [] # <-- ADDED
#Collecting bar_code
for row in url_data:
req_bar = requests.get(row, headers=headers)
ext_bar = BeautifulSoup(req_bar.text, 'html.parser')
#for code_bar in ext_bar.find_all('tbody', {'class' : 'text-left'}): <-- REMOVED
for code_bar in ext_bar.find_all('table'):
table_content_tr = code_bar.findAll('tr')
for td in table_content_tr:
all_data = td.findAll('td')
# all_dt2 = [x.text.strip(' ') for x in all_data] <-- REMOVED
all_dt1 = [x.get_text(strip = True) for x in all_data] # <-- ADDED
# all_data was being overwritten before
all_dt1 = np.ravel(all_dt1) # one dimensional array # <-- ADDED
# check for GTIN, Lot, and date <--- Added here down
if len(all_dt1) < 3:
# check for product GTIN
if not re.match('^(\d{13})$', all_dt1[0, ]):
# add a blank (underscore) for missing GTIN
all_dt1 = np.hstack(('_', all_dt1))
# check the lot field for dates (missing lot)
if re.search('[\d]{2}/[\d]{2}/[\d]{2,4}', all_dt1[1, ]):
all_dt1 = np.insert(all_dt1, 1, "_")
# missing date? any remaining that are missing collected here
s = 3 - len(all_dt1)
for i in range(0, s):
all_dt1 = np.hstack((all_dt1, ['_'])) # append for any other missing fields
# stack new and existing product data
if len(tbler) > 0: # is this the first time through the for loop?
tbler = np.vstack((tbler, all_dt1)) # stack existing rows
else: tbler = all_dt1 # or else, create first row
# ----- end added here
# removed ... don't loop twice
#collecting detailled products
#for data in url_data: <-- REMOVED
# req = requests.get(data, headers=headers) <-- REMOVED
# ext = BeautifulSoup(req.text, 'html.parser') <-- REMOVED
for products in ext_bar.find_all('div', {'class' : 'row site-wrapper'}): # mod!! ext => ext_bar
title = products.find('p', {'class' : 'h5 product-main-title'}).text
brand = products.find('p', {'class' : 'text-muted product-main-brand'}).text.replace('\xa0:\n',': ').strip()
category = products.find('p', {'class' : 'product-cat'}).text
detail_rappel = products.find_all('div', {'class' : 'card product-practical'})
for motif in detail_rappel:
val_1 = motif.find('span', {'class': 'val'}).text
results = row, title, brand, category, val_1 # mod!! data => row, removed *all_data
data_set.append(results)
return data_set, tbler #, all_data <--- MOD, => added tbler
# final result
final, eb = data(url_data)
# column stack the GTIN, lot, and date with the product data
newArr = np.hstack((eb, final))
# this commented out for loop will print by array row
# x, y = np.shape(newArr)
# for i in range(0, x):
# print(newArr[i, ])
# this is just an alternative print method (it doesn't how the brackets or quotes)
for i in newArr:
for j in i:
print(j, end = ' ')
print()
# yet another alternate look at the same inforamtion
print(tabulate.tabulate(newArr))
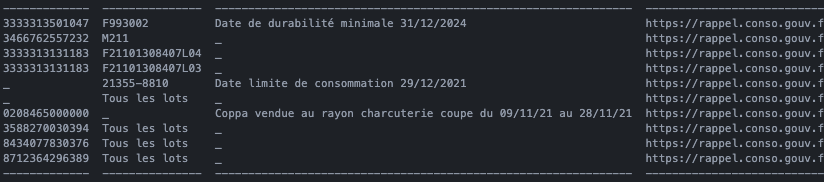
The first coded output snapshot
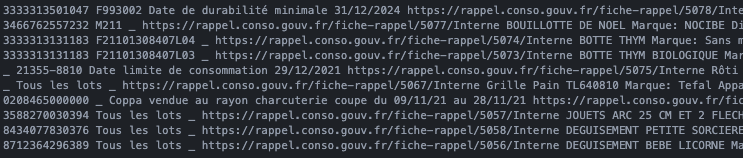
The use of tabulate (two shots since it's so wide)