The link.txt file contains links that I'm looping thru. The links lead to pages that have mp4 files. I am downloading these. It works fine except I cannot grab the original name of the mp4.
Current output for the mp4 file:
videoname.mp4
Desired output for the mp4 file:
V14728_full_h264_1500.mp4
My Code:
one = open("link.txt", "r")
for two in one.readlines():
driver.get(two)
sleep(2)
vid = driver.find_element(By.TAG_NAME, "video")
src = vid.get_attribute("src")
driver.get(src)
sleep(2)
url = driver.current_url
print(url)
urllib.request.urlretrieve(url, 'videoname.mp4') #NEED FIX HERE
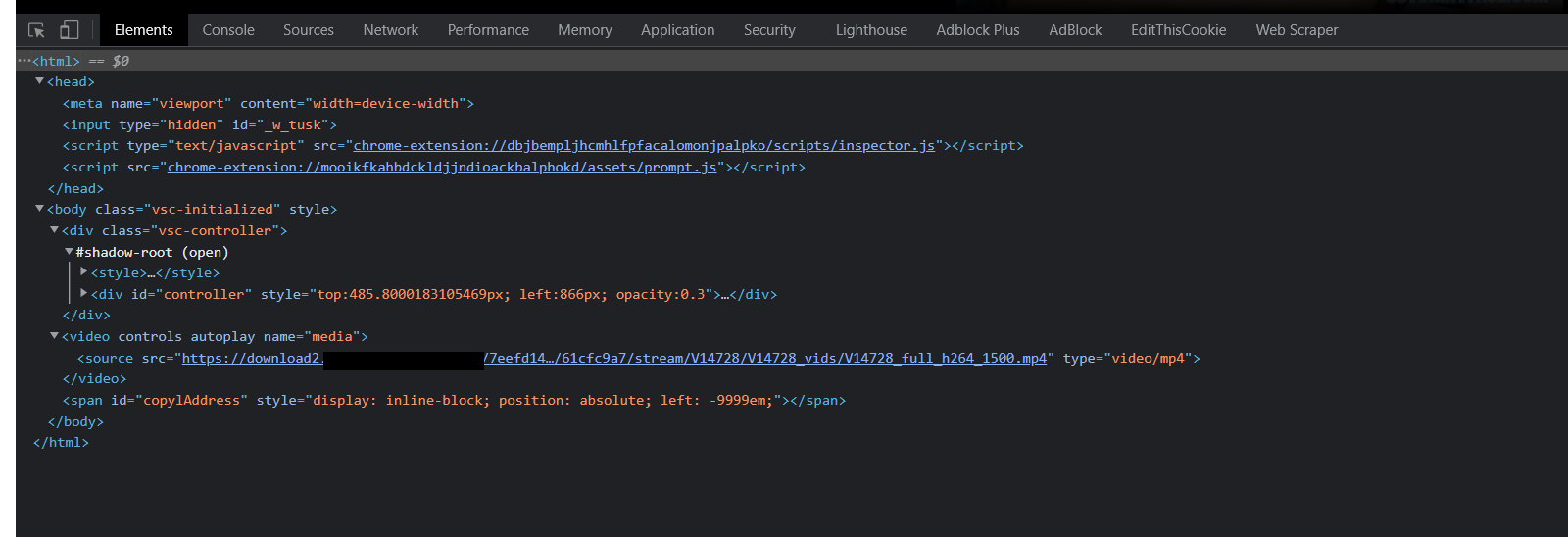
HTML of the page:
<html>
<head>
<meta name="viewport" content="width=device-width">
<input type="hidden" id="_w_tusk">
<script type="text/javascript" src="chrome-extension://dbjbempljhcmhlfpfacalomonjpalpko/scripts/inspector.js">
</script><script src="chrome-extension://mooikfkahbdckldjjndioackbalphokd/assets/prompt.js"></script>
</head>
<body style="">
<div >
</div><video controls="" autoplay="" name="media">
<source src="https://download2.[REDACTED].com/7eefd14b306c441ba17f2bd72e371586/61cfc9a7/stream/V14728/V14728_vids/V14728_full_h264_1500.mp4" type="video/mp4">
</video><span id="copylAddress" style="display: inline-block; position: absolute; left: -9999em;">
</span>
</body>
</html>
CodePudding user response:
To extract the name of the file simply split the url by / and pick the last element from the list:
src="https://download2.[REDACTED].com/7eefd14b306c441ba17f2bd72e371586/61cfc9a7/stream/V14728/V14728_vids/V14728_full_h264_1500.mp4"
src.split('/')[-1]
Output:
V14728_full_h264_1500.mp4
In your example:
urllib.request.urlretrieve(url, src.split('/')[-1])