I have the following table -
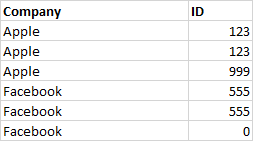
My goal is to return the Company/ID row with the highest "count" respective to a partition done by the ID.
So the expected output should look like this :

My current code returns a count partitioned on all ids. I just want it to return the one with the highest count.
Current code -
select distinct Company, Id, count(*) over (partition by ID)
from table1
where company in ("Facebook","Apple")
My output:

CodePudding user response:
Your base query is incorrect. You partition by ID regardless of the company, but in your request comments you clarify that you want to count per ID and company. This would have to be
select distinct company, id, count(*) over (partition by company, id)
from table1
where company in ('Facebook','Apple');
But that query boils down to be a mere aggregation and doesn't need window functions at all. It is evaluating the count for each single row, only to dismiss duplicates later with DISTINCT. DISTINCT is a costly operation, so why not simply aggregate your rows in the first place?
select company, id, count(*)
from table1
where company in ('Facebook','Apple')
group by company, id;
Now you only want to keep the rows with the highest count per company, and this is where window functions come into play:
select company, id, total
from
(
select
company,
id,
count(*) as total,
max(count(*)) over (partition by company) as max_total
from table1
where company in ('Facebook','Apple')
group by company, id
) aggregated
where total = max_total;
CodePudding user response:
We can use ROW_NUMBER here along with an aggregation query:
WITH cte AS (
SELECT Company, ID, COUNT(*) AS Count,
ROW_NUMBER() OVER (PARTITION BY Company ORDER BY COUNT(*) DESC) rn
FROM table1
GROUP BY Company, ID
)
SELECT Company, ID, Count
FROM cte
WHERE rn = 1;
Here is a running demo for MySQL.
CodePudding user response:
SELECT company, id, COUNT(*)
FROM table1
GROUP BY EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO
HAVING COUNT(*) > 1;