Problem : Things on webpage like AMD Ryzen™ 9 5950X, when i am getting it into csv file it shows up as : AMD Ryzenâ„¢ 9 5950X, 90°C shows up as 90°C. i have to write a function to get the exact(proper) values from the web page. i tried to capture and store these in .txt file. It shows up as perfectly normal values. Is excel/csv creating this problem? How can i solve this issue?
config.ini
[configData]
baseurl = https://www.amd.com/en/processors/ryzen
sub_url = https://www.amd.com
all_keys = Model,Platform,Product Family,Product Line,# of CPU Cores,# of Threads, Max. Boost Clock, Base Clock, Total L2 Cache, Total L3 Cache,Default TDP, Processor Technology for CPU Cores, Unlocked for Overclocking, CPU Socket,Thermal Solution (PIB), Max. Operating Temperature (Tjmax), Launch Date, *OS Support
Main.py file code
import logging
from data_extraction import data_extraction
from data_processing import data_processing
from configparser import ConfigParser
class Main:
def __init__(self):
self.config = ConfigParser()
self.config.read('config.ini')
logging.basicConfig(filename='logfile.log', level=logging.DEBUG,
format='%(asctime)s:%(lineno)d:%(name)s:%(levelname)s:%(message)s')
self.baseurl = self.config['configData']['baseurl']
self.sub_url = self.config['configData']['sub_url']
self.all_keys = self.config['configData']['all_keys']
# print(all_keys)
self.all_keys = [key.strip() for key in self.all_keys.split(',')]
def __Processing__(self):
de = data_extraction(self.baseurl)
dp = data_processing()
self.model_links = de.get_links_in_list(self.sub_url)
logging.debug(self.model_links)
each_link_data = de.data_extraction(self.baseurl, self.all_keys, self.model_links)
logging.info('data extraction is called from main')
all_link_data = dp.data_processing(each_link_data)
# calling function write_to_csv
dp.write_to_csv(all_link_data,self.all_keys)
logging.info('data copied to csv')
dp.rectify_csv(str(all_link_data))
Main().__Processing__()
DataExtraction.py
import logging
import requests
from bs4 import BeautifulSoup
class data_extraction:
def __init__(self, baseurl):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36',
"Upgrade-Insecure-Requests": "1", "DNT": "1",
"Accept": "text/html,application/xhtml xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate"}
r = requests.get(baseurl, headers=self.headers)
status = r.status_code
self.soup = BeautifulSoup(r.content, 'html.parser')
self.model_links = []
# function to get the model links in one list from soup object(1st page extraction)
def get_links_in_list(self, sub_url):
for model_list in self.soup.find_all('td', headers='view-name-table-column'):
# model_list = model_list.a.text - to get the model names
model_list = model_list.a.get('href')
# print(model_list)
model_list = sub_url model_list
# print(model_list)
one_link = model_list.split(" ")[0]
self.model_links.append(one_link)
return self.model_links
# function to get data for each link from the website(2nd page extraction)
def data_extraction(self, baseurl, all_keys, model_links):
r = requests.get(baseurl, headers=self.headers)
status = r.status_code
soup = BeautifulSoup(r.content, 'html.parser')
each_link_data = []
try:
for link in model_links:
r = requests.get(link, headers=self.headers)
soup = BeautifulSoup(r.content, 'html.parser')
specification = {}
for key in all_keys:
spec = soup.select_one(
f'.field__label:-soup-contains("{key}") .field__item, .field__label:-soup-contains("{key}") .field__items .field__item')
# print(spec)
if spec is None:
specification[key] = ''
if key == 'Model':
specification[key] = [i.text for i in soup.select_one('.page-title')]
specification[key] = specification[key][0:1:1]
# print(specification[key])
else:
if key == '*OS Support':
specification[key] = [i.text for i in spec.parent.select('.field__item')]
else:
specification[key] = spec.text
specification['link'] = link
each_link_data.append(specification)
except Exception as e:
print('Error occurred')
logging.info('data not extracted')
return each_link_data
# print(each_link_data)
Data processing.py
import pandas as pd
class data_processing:
# function for data processing : converting the each link object into dataframe
def data_processing(self, each_link_data):
all_link_data = []
for each_linkdata_obj in each_link_data:
# make the nested dictionary to normal dict
norm_dict = dict()
for key in each_linkdata_obj:
if isinstance(each_linkdata_obj[key], list):
norm_dict[key] = ','.join(each_linkdata_obj[key])
else:
norm_dict[key] = each_linkdata_obj[key]
all_link_data.append(norm_dict)
return all_link_data
# function to write dataframe data into csv
def write_to_csv(self, all_link_data, all_keys):
all_link_df = pd.DataFrame.from_dict(all_link_data)
all_link_df2 = all_link_df.drop_duplicates()
all_link_df3 = all_link_df2.reset_index()
# print(all_link_df3)
all_keys = all_keys ['link']
all_link_df4 = all_link_df3[all_keys]
# print(all_link_df4)
all_link_df4.to_csv('final_data.csv', index=False)
# all_link_df4.to_csv('final_data.xlsx',index=False)
# function to remove unwanted characters from the csv file.
def rectify_csv(self, all_link_df4):
all_link_data_str = str(all_link_df4)
with open('readme.txt', 'w') as f:
f.writelines(all_link_data_str)
readme.txt:
'link': 'https://www.amd.com/en/products/cpu/amd-ryzen-9-5950x',
'Platform': 'Boxed Processor',
'Product Family': 'AMD Ryzen™ Processors',
'Product Line': 'AMD Ryzen™ 9 Desktop Processors',
'# of CPU Cores': '16',
'# of Threads': '32',
'Max. Boost Clock': 'Up to 4.9GHz',
'Base Clock': '3.4GHz',
'Total L2 Cache': '8MB',
'Total L3 Cache': '64MB',
'Default TDP': '105W',
'Processor Technology for CPU Cores': 'TSMC 7nm FinFET',
'Unlocked for Overclocking': 'Yes',
'CPU Socket': 'AM4',
'Thermal Solution (PIB)': 'Not included',
'Max. Operating Temperature (Tjmax)': '90°C',
'Launch Date': '11/5/2020',
'*OS Support': 'Windows 10 - 64-Bit Edition,RHEL x86 64-Bit,Ubuntu x86 64-Bit,*Operating System (OS) support will vary by manufacturer.'},
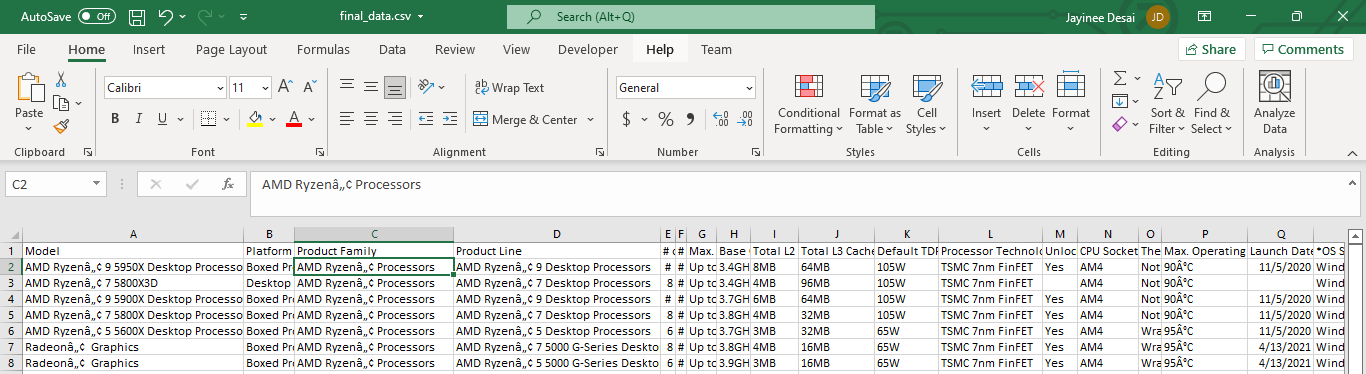
final_data.csv
AMD Ryzenâ„¢ 9 5950X Desktop Processors
AMD Ryzenâ„¢ Processors
AMD Ryzenâ„¢ 9 Desktop Processors
90°C
CodePudding user response:
Microsoft software is infamous for assuming the contents of a file are encoded in the native Windows character encoding. If your file is written in something reasonable like UTF-8 it is likely to be misinterpreted.
The way to get Microsoft applications like Excel to recognize UTF-8 properly is to put a byte order mark at the front of the file. Python can add this automatically if you open the file with encoding='utf_8_sig'.