I want to scrape text from table they will give me data but they will not given me data in these format shown in pic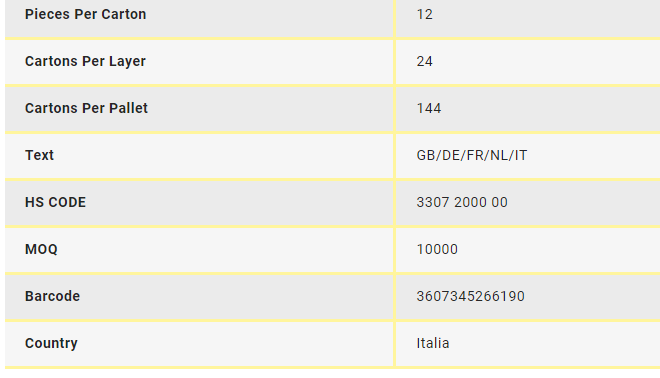
from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'book'
start_urls = ['https://blogsrl.it/gb/4-no-food']
def parse(self, response):
books = response.xpath("//h3/a/@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
rows=response.xpath("//dl[@class='data-sheet']")
details={}
for row in rows:
key = row.xpath('.//dt//text()').get(default='').strip()
value=row.xpath('.//dd/text()').getall()
value = ''.join(value).strip()
details[key] = value
yield details
CodePudding user response:
I think the issue is with your XPATH. Your XPATH will not return you a list instead it will return the string since it's only targeting 1 element.
Perhaps try
rows=response.xpath("//dl[@class='data-sheet']//dt | //dl[@class='data-sheet']//dd ")
CodePudding user response:
In your parse_book callback, the variable rows does not return a list but a single element so you can't loop over it. You need to loop over either the row names or the row values. See below snippet on how you can loop over the row names.
def parse_book(self, response):
rows=response.xpath("//dl[@class='data-sheet']/dt")
details={}
for row in rows:
key = row.xpath("./text()").get()
value=row.xpath("./following-sibling::dd/text()").get()
details[key] = value
yield details