i have 8 csv files the have the same x,y axis with different values. i would like to plot them all on the same plot to compare between them. this is a snap from a ploty code
import pandas as pd
import plotly.express as px
df = pd.read_csv("file1.csv")
df2 = pd.read_csv('file2.csv')
fig = px.line(df, x = 'values', y = 'time')
fig1 = px.line(df2, x = 'values', y = 'time')
fig.show()
fig1.show()
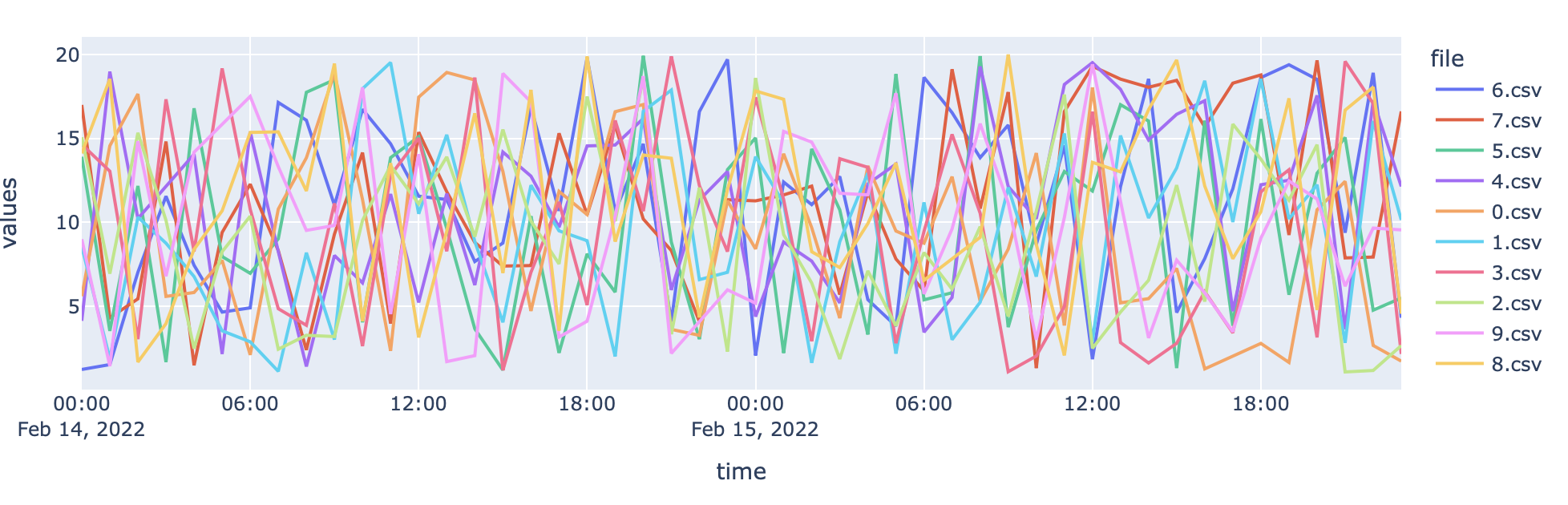
but every csv file is plotted individually i want them to be on the same plot. like this plot
CodePudding user response:
You need to create a unique dataframe with df3=pd.concat([df,df2],axis=0) and use it to create your plot.
If you want to distinguish your two tables in your plot. You can create a new columns in your dataframe:
df["Frame"]="df"
df["Frame"]="df2"
df3=pd.concat([df,df2],axis=0)
And add color option in px.line
fig = px.line(df2, x = 'values', y = 'time',color='Frame')
fig.show()
CodePudding user response:
- have synthesized CSV files to make MWE
- have presented two approaches
- concat all into one data frame then create figure
- create figure and add a trace for each CSV
- in both have used
glob()to get all CSVs in a directory
from pathlib import Path
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
# setup env
f = Path.cwd().joinpath("SO71123005")
if not f.is_dir():
f.mkdir()
# generate some CSVs
for i in range(10):
pd.DataFrame(
{
"time": pd.date_range("14-Feb-2022", freq="1H", periods=48),
"values": np.random.uniform(1, 20, 48),
}
).to_csv(f.joinpath(f"{i}.csv"), index=False)
# create a line trace per CSV file in directory by concatenating all CSVs into data frame
px.line(
pd.concat([pd.read_csv(csv).assign(file=csv.name) for csv in f.glob("*.csv")]),
x="time",
y="values",
color="file",
).show()
# create a figure then add a line for each CSV in directory
fig = go.Figure()
for csv in f.glob("*.csv"):
fig.add_traces(
px.line(pd.read_csv(csv), x="time", y="values")
.update_traces(line_color=None, showlegend=True, name=csv.name)
.data
)
fig