Here's my code:
import glob
import itertools
import sys, os
import six
import csv
import numpy as np
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdftypes import resolve1
os.chdir("PATH/pdf")
extension = 'pdf'
all_filenames = [i for i in glob.glob('*.{}'.format(extension))]
valeur = []
n = 1
for i in all_filenames:
fp = open(i, "rb")
parser = PDFParser(fp)
doc = PDFDocument(parser)
fields = resolve1(doc.catalog["AcroForm"])["Fields"]
for i in fields:
field = resolve1(i)
name, value = field.get("T"), field.get("V")
filehehe = "{0}:{1}".format(name,value)
values = resolve1(value)
names = resolve1(name)
valeur.append(values)
n = n 1
with open('test.csv','wb') as f:
for i in valeur:
f.write(i)
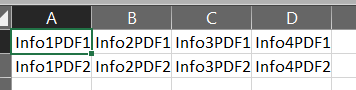
The goal here is to pick up some informations in PDF. Here's the output :
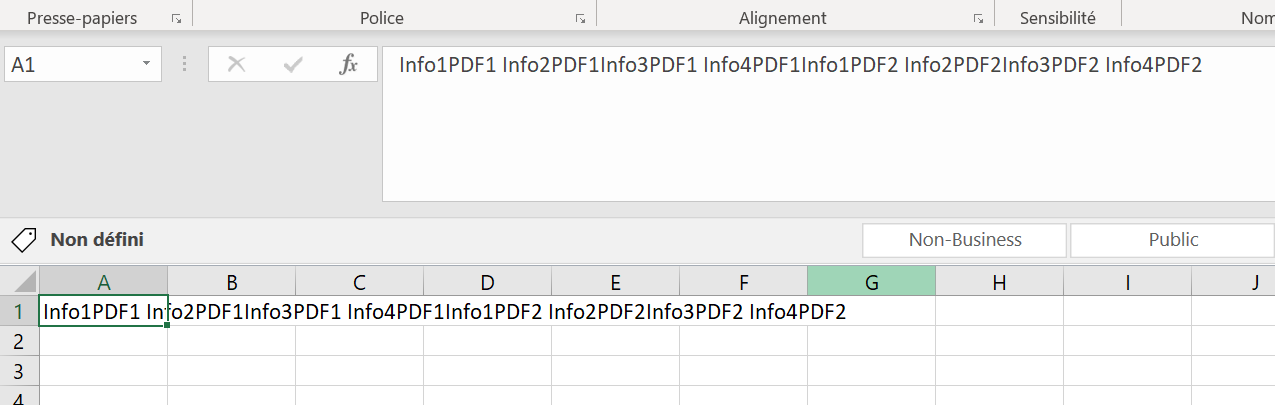
As you can see, the format is not pretty. I'm not very familiar with open() so I'm kind of stuck.
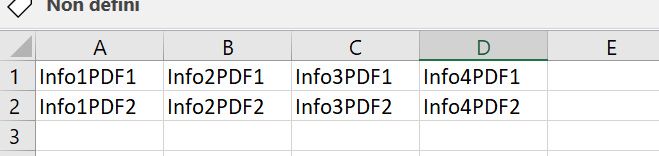
I would like to have distinct rows for each PDF with each informations having her own cell. Something like that :
CodePudding user response:
- Try to store the data from each pdf file in a separate list. And add this list to the
valeurlist which you have. - Use
csvmodule as @martineau rightly suggested.
You can try the with below code.
import csv
valeur = []
#your code
n = 1
for i in all_filenames:
temp_list = []
fp = open(i, "rb")
parser = PDFParser(fp)
doc = PDFDocument(parser)
fields = resolve1(doc.catalog["AcroForm"])["Fields"]
for i in fields:
field = resolve1(i)
name, value = field.get("T"), field.get("V")
filehehe = "{0}:{1}".format(name,value)
values = resolve1(value)
names = resolve1(name)
temp_list.append(values)
n = n 1
valeur.append(temp_list)
#Finally when you have the required data, you can write to csv file like this.
with open('mycsv.csv', 'w', newline='') as myfile:
wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)
for val in valeur:
wr.writerow(val)
With this, the output would be like this