I have a file like this
InputFile.txt
JOB JOB_A
Source C://files/InputFile
Resource 0 AC
User Guest
ExitCode 0 Success
EndJob
JOB JOB_B
Source C://files/
Resource 1 AD
User Current
ExitCode 1 Fail
EndJob
JOB JOB_C
Source C://files/Input/
Resource 3 AE
User Guest2
ExitCode 0 Success
EndJob
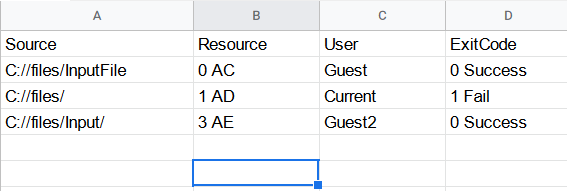
I have to convert the above file to a csv file as below
How to convert it using shell scripting?
CodePudding user response:
I used awk.
The separator is a tabulator because it's more common than a comma in the CSV format.
If you want a coma, you can simply change the \t -> ,.
cat InputFile.txt | \
awk '
BEGIN{print "Source\tResource\tUser\tExitCode"}
/^JOB/{i=0}
/^\s/{
i ;
match($0,/\s*[a-zA-Z]* /);
a[i]=substr($0,RLENGTH RPOS)}
/^EndJob/{for(i=1;i<5;i ) printf "%s\t",a[i];print ""}'
- The first line
BEGINwrites header. - The second line matches
/JOB/and only sets an iteratorias zero. - The third line matches the blank on the start of a line and fills array
awith values (it count on strict count and order of rows). - The fourth part of the awk script matches
EndJoband prints stored values.
Output:
| Source | Resource | User | ExitCode |
|---|---|---|---|
| C://files/InputFile | 0 AC | Guest | 0 Success |
| C://files/ | 1 AD | Current | 1 Fail |
| C://files/Input/ | 3 AE | Guest2 | 0 Success |
Script using associative array:
You can change the script so that uses strict Source, Resource, User, and ExitCode values from $1 (first record) of lines, but it would be a little longer, and this input file doesn't need it.
cat InputFile.txt | \
awk '
BEGIN{
h[1]="Source";
h[2]="Resource";
h[3]="User";
h[4]="ExitCode";
for(i=1;i<5;i ) printf "%s\t",h[i];print ""}
/^\s/{
i ;
match($0,/\s*[a-zA-Z]* /);
a[$1]=substr($0,RLENGTH RPOS)}
/^EndJob/{for(i=1;i<5;i ) printf "%s\t",a[h[i]];print ""}'
CodePudding user response:
with sed ... dont know if the order in the InputFile.txt is always the same as Source, Resource, User, ExitCode, but if it is
declare delimiter=";"
sed -Ez "s/[^\n]*(Source|Resource|User) ([^\n]*)\n/\2${delimiter}/g;s/[ \t]*ExitCode //g;s/[^\n]*JOB[^\n]*\n//gi;s/^/Source${delimiter}Resource${delimiter}User${delimiter}ExitCode\n/" < InputFile.txt > output.csv