I have a dataframe something like this.
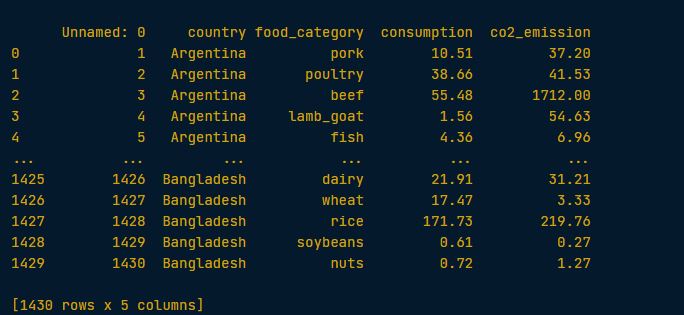
I want to calculate the variance and standard deviation of co2_emission for each food_category by grouping and aggregating. And it has to be in this format
print(food_consumption.____(____)['co2_emission'].agg([____]))
This is I have done so far
print(food_consumption. .....(....)['co2_emission'].agg([np.var(food_consumption['co2_emission'], ddof=1),np.sqrt(np.var(food_consumption['co2_emission'], ddof=1))]))
I have to select the each category of the column named food_category. how to do that?
CodePudding user response:
Because pandas Series.var and Series.std has default ddof=1 pass them to agg:
print(food_consumption.groupby('food_category')['co2_emission'].agg(['var','std']))