I am working on a timetable system and need all the free slots (where the student has no lectures). Right now it prints the entire timetable out. I just need to store all the free slots somewhere. They are showing up as "NaN" on the time table. here is my code.
from bs4 import BeautifulSoup
import pandas as pd
import requests
import time
import natsort as ns
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import Select
s = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=s)
driver.maximize_window() #opens up website, probably not needed.
driver.implicitly_wait(30)
driver.get('https://opentimetable.dcu.ie/')
select = Select(driver.find_element_by_tag_name("select"))
select.select_by_visible_text("Programmes of Study")
search = driver.find_element_by_id("textSearch")
search.send_keys("CASE2")
checkbox = driver.find_element_by_xpath('.//input[following-sibling::div[contains(text(), "CASE2")]]') # it works but it is harder to remeber
checkbox.click()
time.sleep(3)
html = driver.find_element_by_id("week-pdf-content").get_attribute('outerHTML')
df2 = pd.read_html(html)[0]
#trying to print free slots
x = 0
if df2[x] == "NaN":
print(df[x])
x =1
print(df2.to_string()) # to_string() to display all columns without `...`
Expected output would be all the free times printing out. e.g Monday : 11-12, 13-14, 16-17. for each day.
Here is the current output As you can see it is just printing out the timetable. I would like to store all the times where it says NaN
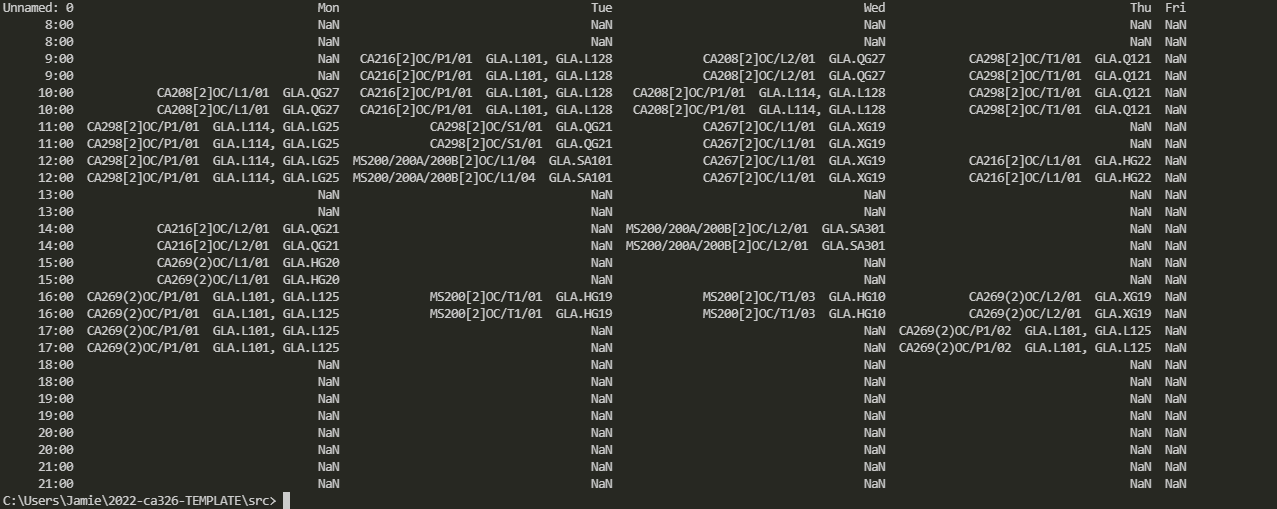
CodePudding user response:
Note: This is just an impulse to adapt, you should then be able to make fine tuning on your own.
Based on your update, I now have an idea of what the output should be. To simply output the information in a similar structure, you can iterate over each column of the dataframe if you have set the first column, that keeps the time, as index.
df = df2.set_index('Unnamed: 0') #or df = df2.set_index(list(df2.columns[[0]]))
for column in df:
print(f'{column}:{", ".join(df[df[column].isna()].index.drop_duplicates().to_list())}')
Output
Mon:8:00, 9:00, 13:00, 18:00, 19:00, 20:00, 21:00
Tue:8:00, 13:00, 14:00, 15:00, 17:00, 18:00, 19:00, 20:00, 21:00
Wed:8:00, 13:00, 15:00, 17:00, 18:00, 19:00, 20:00, 21:00
Thu:8:00, 11:00, 13:00, 14:00, 15:00, 18:00, 19:00, 20:00, 21:00
Fri:8:00, 9:00, 10:00, 11:00, 12:00, 13:00, 14:00, 15:00, 16:00, 17:00, 18:00, 19:00, 20:00, 21:00
To store these infromation in dict:
data = []
for column in df:
data.append({column:df[df[column].isna()].index.drop_duplicates().to_list()})
Output
[{'Mon': ['8:00', '9:00', '13:00', '18:00', '19:00', '20:00', '21:00']}, {'Tue': ['8:00', '13:00', '14:00', '15:00', '17:00', '18:00', '19:00', '20:00', '21:00']}, {'Wed': ['8:00', '13:00', '15:00', '17:00', '18:00', '19:00', '20:00', '21:00']}, {'Thu': ['8:00', '11:00', '13:00', '14:00', '15:00', '18:00', '19:00', '20:00', '21:00']}, {'Fri': ['8:00', '9:00', '10:00', '11:00', '12:00', '13:00', '14:00', '15:00', '16:00', '17:00', '18:00', '19:00', '20:00', '21:00']}]