I have data comes with zip/post code, longitude, latitude info. I want to calculate zip distance between one zip code against the rest then do same recursively without duplicated distance values in python. However, I am able to use geosphere R library for distance calculation. However, my objective is to get zip code distances by coordinate in python. I found GeoPandas, or Geod might provide built-in function to calculate zip coordinate distances but still not getting same out that I got from R implementation. Does anyone knows how to find coordinate distances in python? Can anyone suggest possible workaround to do this? Any thoughts?
minimal data
here is the minimal data that I used in R for distance calculation.
> dput(df)
structure(list(post_code = c(201L, 311L, 312L, 313L, 314L, 315L,
317L, 318L, 319L, 370L, 371L, 372L, 373L, 374L, 390L, 391L, 392L,
396L, 397L, 398L), latitude = c(30.82, 32.08, 32.39, 32.31, 32.38,
32.31, 32.29, 32.14, 32.2, 32.13, 32.29, 32.38, 32.16, 32.16,
32.18, 32.19, 32.19, 32.36, 32.27, 32.07), longtitude = c(-83.03,
-82.62, -82.52, -82.52, -82.52, -82.1, -82.33, -82.92, -82.34,
-82.2, -82.94, -82.82, -82.61, -82.39, -82.58, -82.86, -82.56,
-82.89, -82.69, -82.5)), row.names = c(NA, 20L), class = "data.frame")
current R attempt
here is my current R implementation to calculate distance between different postal code; essentially I want to calculate zip or post code distance between one to another recursively.
library(geosphere)
df_src=df
df_trg=df
colnames(df_src)=c("src_post_code", "src_lat", "src_long")
colnames(df_trg)=c("trg_post_code", "trg_lat", "trg_long")
get_distance <- function(post_code, radius=1e-5){
tmp=df_src[df_src$src_post_code==post_code,]
dist=distHaversine(tmp[,1:2,with=FALSE],df_trg[,1:2,with=FALSE])
res= as.data.frame(
post_code=df_src$src_post_code,
lat=df_src$src_lat
long=df_src$src_long
dist= dist*1e-5
)
return(res)
}
final_output= as.data.frame(lapply(df_src$src_post_code, get_distance))
but doing this way is not very efficient, because actual list of post code are 40k and doing this calculation gave me computational burden even using parallel processing.
However, my objective is doing this in python by ingesting above R logic. I think Geod or GeoPandas might help me with that, still getting same output in python. Can anyone point me out how to find zip/post code coordinate distance between one to another recursively? Any thoughts?
recursively I mean is like this graph below:
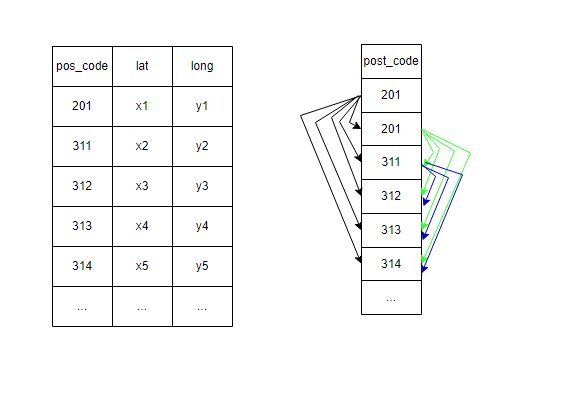
so tabular view on the left shows how original input data looks like; the graph on the right shows how I want to find coordinate distance one to rest recursively in python.
current python attempt:
from pyproj import Geod
import pandas as pd
gist='https://gist.githubusercontent.com/adamFlyn/8f89821df2c09e3196849095d6203e07/raw/6348a43252966be69d4e2c826aaa1c39e113c899/zip_code_data.csv'
df= pd.read_csv(gist, index_col=0)
df_coord = df[['src_lat', 'src_long', 'trg_lat', 'trg_long']].to_numpy().T
df['dist'] = wsg84.inv(*df_coord )[-1] / 1000
but output is not same as the one from R code. Can anyone suggest better way of doing this? Any better idea or approach to do this efficiently in python?
update
I tried @Benoit Fgt' solution below on actual data which has 40k zip code and lan/long info, and it gave me memory error instead. Is there way to do parallel processing in python? Any idea?
CodePudding user response:
I am not sure what is the expected output from the sample. How about something like this (the code can be improved I guess):
from pyproj import Geod
import pandas as pd
import itertools
geod = Geod(ellps="WGS84")
gist='https://gist.githubusercontent.com/adamFlyn/8f89821df2c09e3196849095d6203e07/raw/6348a43252966be69d4e2c826aaa1c39e113c899/zip_code_data.csv'
df = pd.read_csv(gist)
coords = list(zip(df.latitude, df.longtitude, df.post_code))
b = list(itertools.combinations(coords, 2))
lons1 = [k[0][0] for k in b]
lats1 = [k[0][1] for k in b]
lons2 = [k[1][0] for k in b]
lats2 = [k[1][1] for k in b]
az12, az21, dist = geod.inv(lons1, lats1, lons2, lats2)
pairs = [(k[0][2], k[1][2]) for k in b]
pd.DataFrame(list(zip(pairs, dist)), columns=['pos_code', 'dist']).sort_values('dist')
This results to:
pos_code dist
38 (312, 314) 145.395037
54 (313, 314) 1017.765195
37 (312, 313) 1163.160201
29 (311, 373) 1601.912638
100 (317, 319) 1744.891723
... ... ...
96 (315, 396) 88226.021581
86 (315, 318) 91606.658285
89 (315, 371) 93807.304276
8 (201, 370) 94573.135189
4 (201, 315) 106058.180885
CodePudding user response:
Not a full answer, just to test
Try with sklearn:
from sklearn.neighbors import BallTree, DistanceMetric
# gist='https://gist.githubusercontent.com/adamFlyn/...'
df = pd.read_csv(gist, index_col=0)
coords = np.radians(df[['latitude', 'longtitude']])
dist = DistanceMetric.get_metric('haversine')
tree = BallTree(coords, metric=dist)
distances, indices = tree.query(coords, k=len(df))
Do you have memory error with this code?