I have a CSV file with 3 rows: "Username", "Date", "Energy saved" and I would like to sum the "Energy saved" of a specific user by date.
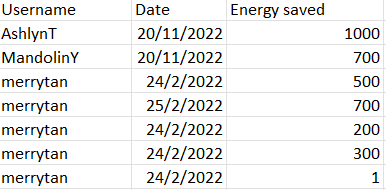
For example, if username = 'merrytan', how can I print all the rows with "merrytan" such that the total energy saved is aggregated by date? (Date: 24/2/2022 Total Energy saved = 1001 , Date: 24/2/2022 Total Energy saved = 700)
I am a beginner at python and typically, I would use pandas to resolve this issue but it is not allowed for this project so I am at a complete loss on where to even begin. I would appreciate any help and guidance. Thank you.
CodePudding user response:
I would turn your CSV file into a two-level dictionary, with username and then date as the keys
infile = open("data.csv", "r").readlines()
savings = dict()
# Skip the first line of the CSV, since that has the column names
# not data
for row in infile[1:]:
username, date_col, saved = row.strip().split(",")
saved = int(saved)
if username in savings:
if date_col in savings[username]:
savings[username][date_col] = savings[username][date_col] saved
else:
savings[username][date_col] = saved
else:
savings[username] = {date_col: saved}
CodePudding user response:
My alternative to opening csv files is to use csv module of native python. You read them as a "file" and just extract the values that you need. I filter using the first column and keep only keep the equal index values from the concerned column. (which is thrid and index 2.)
import csv
energy_saved = []
with open(r"D:\test_stack.csv", newline="") as csvfile:
file = csv.reader(csvfile)
for row in file:
if row[0]=="merrytan":
energy_saved.append(row[2])
energy_saved = sum(map(int, energy_saved))
Now you have a list of just concerned values, and you can sum them afterwards.
Edit - So, I just realized that I left out the time part of your request completely lol. Here's the update.
import csv
energy_saved = []
date = []
with open(r"D:\test_stack.csv", newline="") as csvfile:
file = csv.reader(csvfile)
for row in file:
if row[0]=="merrytan":
date.append(row[1])
energy_saved.append(row[2])
So, we need to get the date column of the file as well. Now you have two lists for two columns with data for Merry Tan. We need to make a presentation of two "rows" but when Pandas has been prohibited, we will go to dictionary with date as keys and energy as values.
But your date column has repeated values (regardless intended or else) and Dictionaries require keys to be unique. So, we use a loop.
my_dict = {}
for k, v in zip(date, energy_saved):
my_dict[k] = my_dict.get(k, 0) int(v)
You add one date value after another as key and corresponding energy as value to the new dictionary, but when it is already present, you will sum with the existing value instead.