I'm trying to work with a file
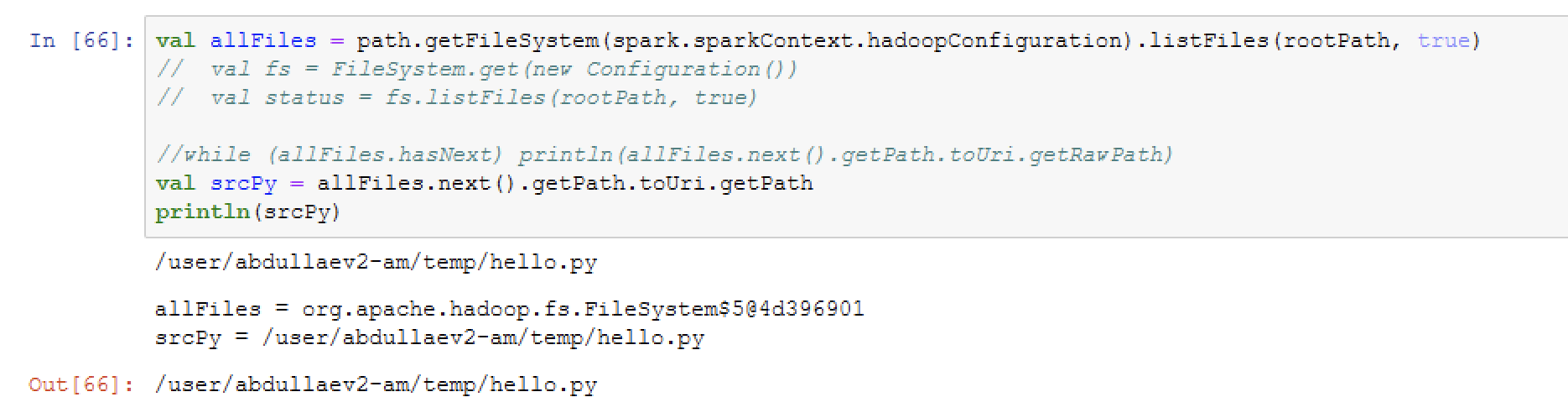
But when I try to access this file, I get an error: No such file or directory
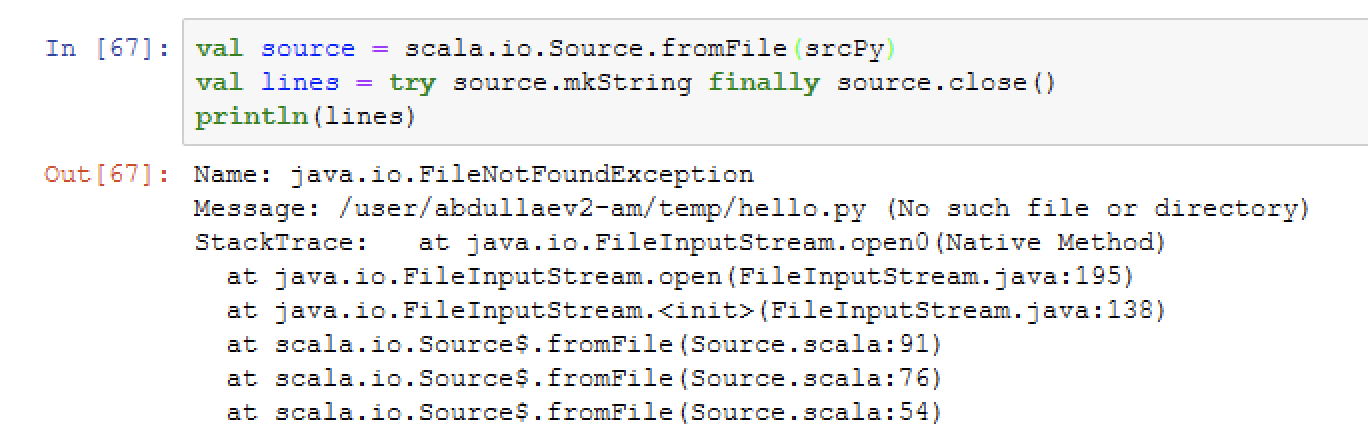

Can you tell me how to access files in hdfs correctly?
UPD:
The author of the answer directed me in the right direction. As a result, this is how I execute the python script:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#import pandas as pd
import sys
for line in sys.stdin:
print('Hello, ' line)
# this is hello.py
And Scala application:
spark.sparkContext.addFile(getClass.getResource("hello.py").getPath, true)
val test = spark.sparkContext.parallelize(List("Body!")).repartition(1)
val piped = test.pipe(SparkFiles.get("./hello.py"))
val c = piped.collect()
c.foreach(println)
Output: Hello, Body!
Now I have to think about whether, as a cluster user, I can install pandas on workers.
CodePudding user response:
I think you should try directly referencing the external file rather than attempting to download it to your Spark driver just to upload it again
spark.sparkContext.addFile(s"hdfs://$srcPy")