I want to convert text to csv. Input file contains 10000K lines. Sample of input file is as below:-
Item=a
Price=10
colour=pink
Item=b
Price=20
colour=blue Pattern=checks
My output should look like this
Item Price Colour Pattern
a 10 pink
b 20 blue checks
I am getting output if there is only single '=' in 1 line, if there are more than 1 like 2/3 '=' then I am not sure how to apply for loop. Can someone check my for loop part? Am I going wrong somewhere?
import csv
import glob
import os
def dat_to_csv(filename, table_name):
with open(filename, 'r') as reader:
list_of_columns = []
table_values = []
master_table = []
counter = 0
for line in reader:
#stripped_line = line.strip()
if line == "\n":
#copy all elements which have values else paste a null
if (table_values):
#master_table.append(table_values)
master_table.append([])
master_table[counter] = table_values.copy()
counter=counter 1
length = len(table_values)
for element in range(length):
table_values[element] = []
continue
if line == "\n":
continue
extra_stripped_line = ' '.join(line.split())
data = extra_stripped_line.split("=",1)
column_name = data[0].strip()
if "=" in data[1]:
data1 = data[1].split(" ",1)
value = data1[0].strip()
data2 = data1[1].split("=",1)
column_name = data2[0].strip()
value = data2[1].strip()
continue
value = data[1].strip()
if column_name not in list_of_columns:
list_of_columns.append(column_name)
table_values.append([])
index = list_of_columns.index(column_name)
#table_values[index].append(value)
table_values[index] = value
#with open("output\\{}.csv".format(table_name), 'w', newline='') as csvfile:
with open("folderpath\\{}.csv".format(table_name), 'w', newline='') as csvfile:
writer = csv.writer(csvfile, delimiter=',', quotechar='"', quoting=csv.QUOTE_ALL)
writer.writerow(list_of_columns)
#t_table_values = zip(*table_values)
max_elements = len((master_table))
master_table_transp = []
for cntr in range(max_elements):
master_table_transp.append([])
num_objects = len(master_table)
for cntr_obj in range(num_objects):
for cntr_row in range(max_elements):
if (cntr_row<len(master_table[cntr_obj])):
master_table_transp[cntr_row].append(master_table[cntr_obj][cntr_row])
else:
master_table_transp[cntr_row].append([])
t_table_values = zip(*master_table_transp)
for values in t_table_values:
writer.writerow(values)
if __name__ == '__main__':
path = "folderpath"
for filename in glob.glob((os.path.join(path, '*.txt'))):
name_only = os.path.basename(filename).replace(".txt", "")
dat_to_csv(filename, name_only)
Output which I am getting is as below:
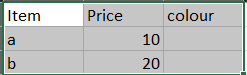
CodePudding user response:
With some assumptions this works. I added some test cases. This does require all the records to fit in memory, but if you know all the possible column names in advance you can set columns accordingly and write the lines as generated instead of all at the end. Even with 10000K (10M) records unless the records are really large that will easily fit in a modern system memory.
input.csv
Item=a
Price=10
Item=b
Price=20
colour=blue Pattern=checks
Item=c
Price=5
Item=d Price=25 colour=blue
Item=e colour===FANCY== Price=1/2=$1
test.py
from collections import defaultdict
import csv
columns = {}
lines = []
with open('input.txt') as fin:
for line in fin:
if not line.strip(): # write record on blank line
needs_flush = False
lines.append(columns)
# blank all the columns to start next record.
columns = {k:'' for k in columns}
continue
# assume multiple items on a line are separated by a single space
items = line.strip().split(' ')
# assume column name is before first = sign in each item
for column,value in [item.split('=',1) for item in items]:
needs_flush = True
columns[column] = value
# write record on EOF if hasn't been flushed
if needs_flush:
lines.append(columns)
# dump records to CSV
with open('output.csv','w',newline='') as fout:
writer = csv.DictWriter(fout, fieldnames=columns)
writer.writeheader()
writer.writerows(lines)
output.csv:
Item,Price,colour,Pattern
a,10,,
b,20,blue,checks
c,5,,
d,25,blue,
e,1/2=$1,==FANCY==,
CodePudding user response:
Unless I've misunderstood something then it's as simple as this:
from pandas import DataFrame
from numpy import nan
master = [dict()]
with open('foo.txt') as foo:
for line in foo:
if (line := line.strip()):
for token in line.split():
k, v = token.split('=')
master[-1][k] = v
elif master[-1]:
master.append(dict())
if not master[-1]:
del master[-1]
if master:
df = DataFrame(master).replace(nan, '', regex=True)
df.to_csv('foo.csv', index=False)
Output (of the csv file):
Item,Price,colour,Pattern
a,10,pink,
b,20,blue,checks
CodePudding user response:
I like to make little state machines for these kinds of problems, since as much as we'd all like to believe the sample data matches the real world, there are probably some gotchas, and you want a solution that's flexible.
For me, that flexibility means as I'm looping over the input lines:
- avoid many nested structures
- do all processing in one place; at the end of the loop, once I know this line is worth processing
- for processing, try to break down the steps and still keep a flat/linear flow...
- how do I go from a line to fields?
- how do I go from a field to a key/value pair?
- how do I use the key-value pair?
And as you try it out, try starting out with smaller samples of your input and build up to the whole, big thing.
#!/usr/bin/env python3
import csv
field_names = {} # use dict as ordered set to collect all field names as data is parsed
records = []
with open('input.txt') as f:
record = None
for line in f:
line = line.strip()
if line.startswith('Item'):
record = {}
if record is None:
continue
if line == '':
records.append(record)
record = None
continue
# Finally, line must be data in a record, parse it
fields = line.split(' ')
kvps = [field.split('=', 1) for field in fields] # 1 in split('=', 1) is for the `===FANCY==` example @MarkTolonen threw at us
kvp_dict = dict(kvps)
record.update(kvp_dict)
field_names.update(kvp_dict) # pass in keys & vals (it's simpler) even if we only need the keys
# Deal with "straggling record" (if your input ends with a line of data (and not an empty line))
if record is not None:
records.append(record)
out_f = open('output.csv', 'w', newline='')
writer = csv.DictWriter(out_f, fieldnames=field_names)
writer.writeheader()
writer.writerows(records)
Here's my output.csv:
| Item | Price | colour | Pattern |
|------|--------|-----------|---------|
| a | 10 | pink | |
| b | 20 | blue | checks |
| aa | 10 | | |
| bb | 20 | blue | checks |
| cc | 5 | | |
| dd | 25 | blue | |
| ee | 1/2=$1 | ==FANCY== | |