I want to add a piece of code to the already existing code that checks if the High column values are greater than of the other values of the rows for the columns Open, Low, Close. I also want to do a checkup to see if the Low columns row values are lower than of the other columns Open, High, Close columns rows values. So in row 1 of The value for the High column does not meet this criteria as the Open and Close values are higher than it so it is in the expected output. So essentially this code is supposed to checkup if each of High value remains to be the greatest value and the Low value is the lowest for each row.
Code:
import pandas as pd
import numpy as np
import time
import datetime
A =[[1645661520000, 37352.0, 37276.5, 37252.0, 37376.0, 15.56119087],
[1645661580000, 37376.0, 37414.0, 37376.0, 37314.0, 49.38248589],
[1645661640000, 37414.0, 37414.0, 37350.0, 37350.0, 45.70306699],
[1645661700000, 37350.0, 37374.0, 37350.0, 37373.5, 14.4306948],
[1645661760000, 37373.5, 36588.0, 37373.5, 37388.0, 3.59340947],
[1645661820000, 37388.0, 37388.0, 37388.0, 39388.0, 21.45525727]]
column_names = ["Unix","Open", "High","Low", "Close", "Volume"]
df = pd.DataFrame(A, columns=column_names)
df.insert(1,"Date", pd.to_datetime(df["Unix"].to_numpy()/1000,unit='s'))
display(df)
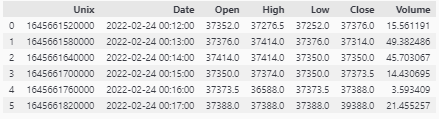
Expected Output:
Rows: 1, 5, 6
#Row 1 is low column is the highest of all than all the other rows
#Row 5 the High column is lower than the other columns
#Row 6 the low column is higher than the other columns
CodePudding user response:
Try this:
# columns of interest
val_cols = ['Open', 'High', 'Low', 'Close']
# This is where High condition is violated
high_cond_violated = df['High'] < df[val_cols].max(axis=1)
# This is where Low condition is violated
low_cond_violated = df['Low'] > df[val_cols].min(axis=1)
# These are the indices where either condition is violated
(df.index[high_cond_violated | low_cond_violated] 1).values.tolist()
output:
[1, 2, 5, 6]
You can call them separately to see which one is actually violated eg
# Only High condition violated
(df.index[high_cond_violated] 1).values.tolist()
...