I want to crawl one website but I have a problem with looping trough page. I want to create a system that collects all links, then click on each link and collects data (date in this case). I wrote a code but I keep getting this error:
StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
(Session info: chrome=98.0.4758.109)
I have tried to increase the sleep interval but the result is the same. The error happens after on second iteration (after first link).
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requests
import time
# url for crawling
url = "https://bstger.weblaw.ch/?size=n_60_n"
# path to selenium
path = 'path to selenium'
driver = webdriver.Chrome(path)
driver.get(url)
time.sleep(4)
# click on search button
buttonClickSearch = driver.find_element_by_xpath('//*[@id="root"]/div/div/div[2]/div[1]/div/div[3]/form/div/input').click()
time.sleep(3)
# get all links
all_links = driver.find_elements_by_tag_name('li.sui-result div.sui-result__header a')
print(all_links)
print()
# loop trough links and crawl them
for link in all_links:
# click on link
print(link)
time.sleep(4)
click = link.click() # I GET THE ERROR HERE ON SECOND ITERATION
time.sleep(4)
# get date
date = driver.find_element_by_tag_name('div.filter-data button.wlclight13').text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
print()
# click on back button
back_button = driver.find_element_by_xpath('//*[@id="root"]/div/section[1]/div[1]/div[1]/a').click()
time.sleep(4)
#scroll
driver.execute_script("window.scrollTo(0, 200)")
CodePudding user response:
Instead of elements get the href value and use driver.get() to navigate.
//Get the href value
all_links =[link.get_attribute('href') for link in driver.find_elements_by_css_selector('li.sui-result >.sui-result__header> a')]
print(all_links)
for link in all_links:
driver.get(link)
driver.refresh()
# get date
date = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div.filter-data button.wlclight13"))).text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
If you want to go ahead with your code you need to re-assigned your element like below.
all_links = driver.find_elements_by_tag_name('li.sui-result div.sui-result__header a')
print(all_links)
print()
# loop trough links and crawl them
for link in range(len(all_links)):
#Re-assined it again
all_links = driver.find_elements_by_tag_name('li.sui-result div.sui-result__header a')
# click on link
print(all_links[link])
time.sleep(4)
all_links[link].click()
time.sleep(4)
# get date
date = driver.find_element_by_tag_name('div.filter-data button.wlclight13').text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
print()
# click on back button
back_button = driver.find_element_by_xpath('//*[@id="root"]/div/section[1]/div[1]/div[1]/a').click()
time.sleep(4)
#scroll
driver.execute_script("window.scrollTo(0, 200)")
Update:
Navigating url not refreshing the page. added driver.refresh() to appear the date.
all_links =[link.get_attribute('href') for link in driver.find_elements_by_css_selector('li.sui-result >.sui-result__header> a')]
print(all_links)
for link in all_links:
driver.get(link)
driver.refresh()
# get date
date = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div.filter-data button.wlclight13"))).text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
You need to import below library.
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
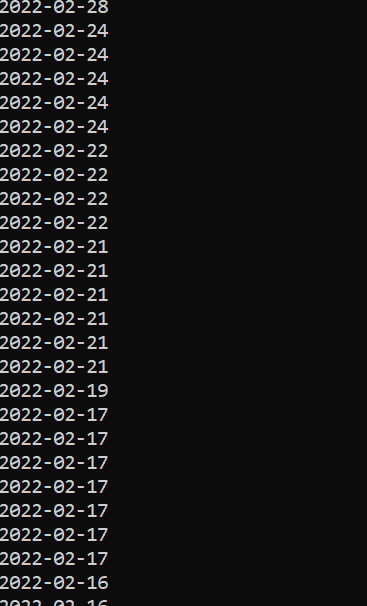
Output:
CodePudding user response:
As already mentioned clicking on Back button is unstable. But can use the Next button to navigate to other links.
And better to apply some Explicit waits.
driver.get("https://bstger.weblaw.ch/?size=n_60_n")
wait = WebDriverWait(driver,30)
actions = ActionChains(driver)
buttonClickSearch = wait.until(EC.element_to_be_clickable((By.XPATH,"//input[@aria-label='search button']")))
actions.move_to_element(buttonClickSearch).click()
time.sleep(5)
all_links = driver.find_elements(By.XPATH,"//div[@class='sui-result__header']/a")
all_links[0].click() # Click on the First link.
for i in range(20):
...
next = wait.until(EC.element_to_be_clickable((By.XPATH,"//button[contains(@class,'next')]")))
next.click() # Click on next link for 20 iterations.